华为云AI开发平台ModelArts标准化_云淘科技
概述 对数据集的某些数值列,根据均值和方差进行标准化。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数据集 参数说明 参数 …

共21项
概述 对数据集的某些数值列,根据均值和方差进行标准化。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数据集 参数说明 参数 …
概述 对数据集的指定列进行StringIndexer编码,即标签编码。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数据集 …
概述 奇异值分解(Singular Value Decomposition,SVD)一般用于数据挖掘、建模等领域的特征工程过程,是线性代数中一种重要的矩阵分解方法,奇异值分解算子可将1个矩阵分解为3个矩阵。 比如对于m×n 的矩阵A,可根据…
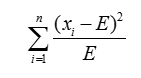
概述 采用卡方检验来进行特征选择。 卡方检验(Chi-Squared Test或χ2 Test)的基本思想是通过特征变量与目标变量之间的偏差大小来选择相关性较大的特征变量。首先假设两个变量是独立的,然后观察实际值与理论值的偏差程度,该偏差程…
概述 “二值化”节点用于将数值型的字段转换成二值化形式。 例如:数据集中有一列整型数据属性为“Age”,取值为:“20-40”,设置阈值为30。二值化后当“Age”小于等于“30”时,“Age”这一列的取值就为“0”;当“Age”大于“30…
概述 “派生”节点用于在数据集中生成任意可行的新属性字段,对现有数据的某个属性操作,例如2*某个属性、两个属性乘积等,允许用户自定义生成属性名称,并将生成的新属性字段添加到原数据集中。 输入 参数 子参数 参数说明 inputs dataf…
概述 将对应列的数据乘以相应的权重得到新的列,只支持数字列。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数据集 参数说明 …
概述 “FP-Growth”节点用于挖掘频繁模式,该算法使用了一种称为频繁模式树(Frequent Pattern Tree)的数据结构。FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。FP-Growth算法基于以上的结构加快…
概述 将数据集指定的某些数字列,转换到一定的数值范围(例如0和1之间)。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数据集…
概述 使用p范式对向量进行正则化。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 spark pipeline类型的模型 参数…
