华为云AI开发平台ModelArts过滤式特征选择_云淘科技

概述 过滤式特征选择根据特征对标签的重要性对特征进行筛选,特征重要性较高的特征,提升训练的精度和效率。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataF…

共21项
概述 过滤式特征选择根据特征对标签的重要性对特征进行筛选,特征重要性较高的特征,提升训练的精度和效率。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataF…

概述 用线性模型计算训练数据的特征重要性。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 特征的重要性和特征在线性模型中的we…
二值化 卡方选择 派生 特征转换 FP-growth 最小最大规范化 正则化 独热编码 主成分分析 离散化 标准化 字符串标签化 奇异值分解 过滤式特征选择 线性特征重要性 特征尺度变换 特征异常检测 特征异常平滑 gbdt编码模型训练 g…
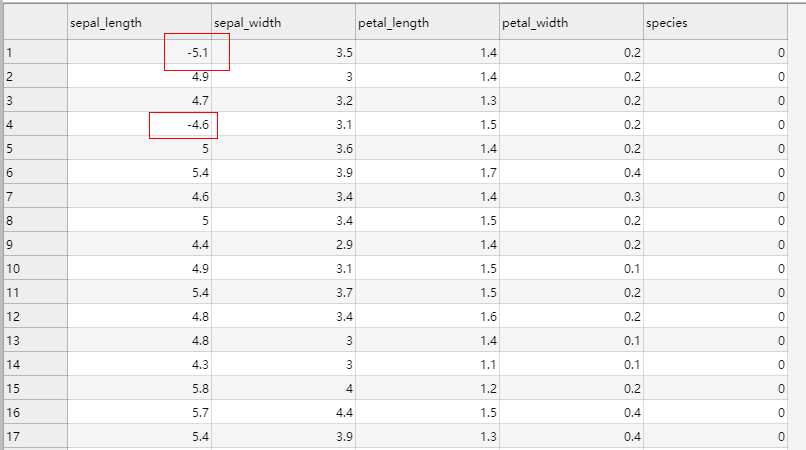
概述 支持对稠密或稀疏的数值类特征进行常见的尺度变换,支持常见的log2、log10、ln、abs及sqrt等尺度变化函数。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pys…

概述 特征异常检测的方法包括箱型图(Box-plot)和AVF(Attribute Value Frequency) 箱型图用于检测连续值类特征的数据,根据四分位数检测异常特征。 AVF用于检测枚举值类特征的数据,根据枚举特征的取值频率及阈…
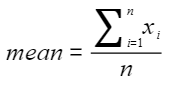
概述 特征异常平滑算子用于将数据中的异常数据平滑到一定的区间,可选择采用箱线图、阈值、百分位和z-score的方法确定平滑区间。 z-score方式:计算所需要平滑的特征的均值mean和标准差std,并引入置信因子cl 平滑区间上界: 平滑…

概述 利用训练好的gbdt分类模型对输入的特征进行离散化处理。对每棵树的叶子节点进行编码,预测的时候遍历到叶子节点对应位置的编码为1,该树其余节点的编码为0。该节点主要用于生产gbdt的分类模型,并存储到输入参数对应的位置上。 输入 参数 …

概述 利用训练好的gbdt分类模型对输入的特征进行离散化处理。对每棵树的叶子节点进行编码,预测的时候遍历到叶子节点对应位置的编码为1,该树其余节点的编码为0。该节点主要用于读取gbdt编码模型训练阶段保存的模型,并对数据进行离散化编码。 输…
概述 根据用户输入的桶的个数,按照分位数分桶,将用户指定的某个数值列离散化。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数…
概述 对数据集的某些数值列,根据均值和方差进行标准化。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数据集 参数说明 参数 …
