华为云AI开发平台ModelArts模型开发简介_云淘科技

AI模型开发的过程,称之为Modeling,一般包含两个阶段: 开发阶段:准备并配置环境,调试代码,使代码能够开始进行深度学习训练,推荐在ModelArts开发环境中调试。 实验阶段:调整数据集、调整超参等,通过多轮实验,训练出理想的模型,…

共54项
AI模型开发的过程,称之为Modeling,一般包含两个阶段: 开发阶段:准备并配置环境,调试代码,使代码能够开始进行深度学习训练,推荐在ModelArts开发环境中调试。 实验阶段:调整数据集、调整超参等,通过多轮实验,训练出理想的模型,…

登录ModelArts管理控制台。 在左侧导航栏中,选择“训练管理 > 训练作业”,进入“训练作业”列表。 在“训练作业”列表中,单击作业名称,进入训练作业详情页 在训练作业详情页的左侧,可以查看此次训练作业的基本信息和算法配置的相关…
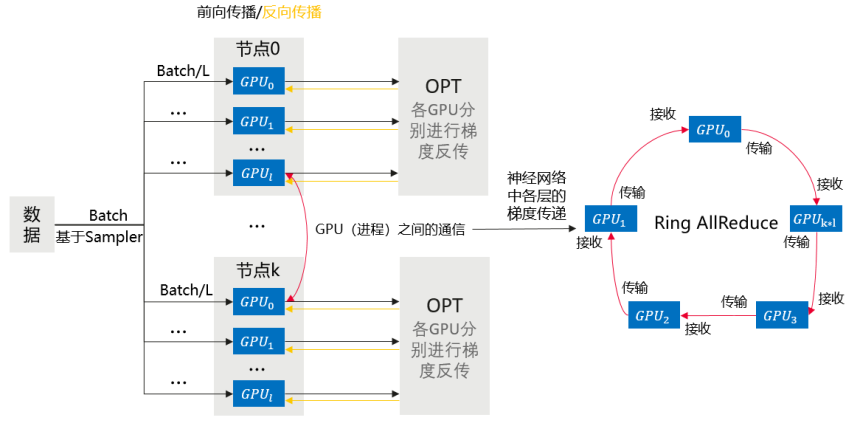
本章节介绍基于Pytorch引擎的多机多卡数据并行训练。 训练流程简述 相比于DP,DDP能够启动多进程进行运算,从而大幅度提升计算资源的利用率。可以基于torch.distributed实现真正的分布式计算,具体的原理此处不再赘述。大致的…
ModelArts支持在新版开发环境中开启TensorBoard和MindInsight可视化工具。在开发环境中通过小数据集训练调试算法,主要目的是验证算法收敛性、检查是否有训练过程中的问题,方便用户调测。 ModelArts可视化作业支持…

Ascend场景日志说明 使用Ascend资源运行训练作业时,会产生Ascend相关日志。Ascend训练场景下会生成device日志、plog日志、proc log单卡训练日志、MindSpore日志、普通日志。 其中,Ascend训练场…
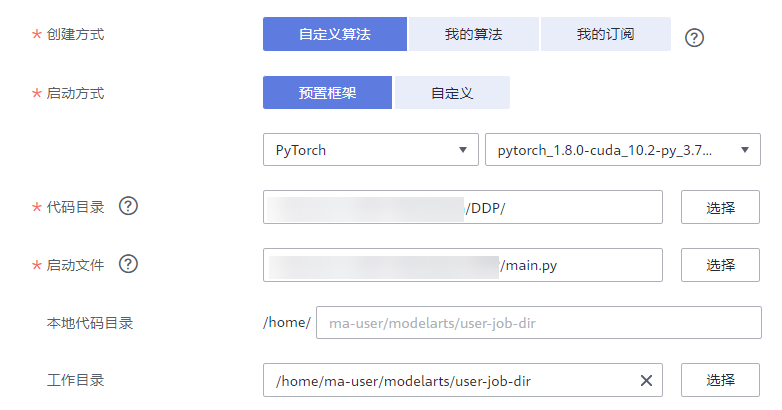
以下对resnet18在cifar10数据集上的分类任务,给出了分布式训练改造(DDP)的完整代码示例。 训练启动文件main.py内容如下(若需要执行单机单卡训练任务,则将分布式改造的代码删除): import datetime impo…

在训练作业详情页,训练日志窗口提供日志预览、日志下载、日志中搜索关键字、系统日志过滤能力。 预览 系统日志窗口提供训练日志预览功能,并支持查看不同计算节点日志,您可以通过右侧下拉框选择目标节点预览。 图1 查看不同计算节日志 当日志文件过大…

本文介绍三种使用训练作业来启动PyTorch DDP训练的方法及对应代码示例: 使用PyTorch预置框架功能,通过mp.spawn命令启动 使用自定义镜像功能 通过torch.distributed.launch命令启动 通过torch….
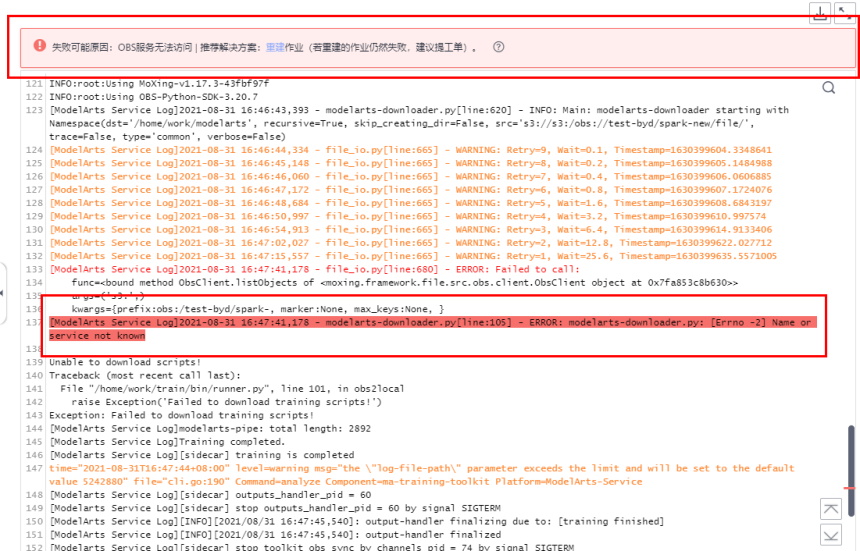
在ModelArts中训练作业遇到问题时,可首先查看日志,多数场景下的问题可以通过日志报错信息直接定位。 ModelArts提供了训练作业失败定位与分析功能,如果训练作业运行失败,ModelArts会自动识别导致作业失败的原因,在训练日志界…

本文介绍了使用训练作业的自定义镜像+自定义启动命令来启动PyTorch DDP on Ascend加速卡训练。 前提条件 需要有Ascend加速卡资源池。 创建训练作业 本案例创建训练作业时,需要配置如下参数。 表1 创建训练作业的配置说明…
