华为云AI开发平台ModelArts文章相似度_云淘科技

概述 支持cosine、levenshtein、jaccard和最长公共子序列四种方法计算文章的相似度。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的Data…

共18项
概述 支持cosine、levenshtein、jaccard和最长公共子序列四种方法计算文章的相似度。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的Data…

概述 支持cosine、levenshtein、jaccard、最长公共子序列、minhash_sim、ssk、simhash_hamming_sim七种方法计算字符串的相似度。 输入 参数 子参数 参数说明 inputs dataDF i…
概述 支持cosine、levenshtein、jaccard、最长公共子序列、minhash_sim、ssk、simhash_hamming_sim七种方法计算 文章的相似度 输入 参数 子参数 参数说明 inputs dataDF in…

概述 将分词后的句子生成连续N个词的NGram短语,并进行全局个数的统计,支持权重列输入。 输入 参数 子参数 参数说明 inputs input_table 输入表表名,输入的包含分词后的句子的数据表;必填; inputs vocab_t…

概述 承接分词结果,计算一个文档里单词两两之间的互信息值(PMI)。PMI计算公式如下: 相关概念解释: 共现对儿:一句话里面如果两个词在句子里的距离小于等于定义的滑动窗口大小,则这两个词共现形成共现对儿。 P(x,y):x,y为两个词,P…
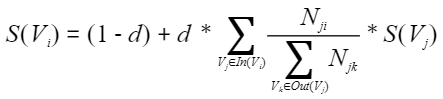
概述 承接分词结果,获取各个文档中的关键词。 原理 该算法基于TextRank,依据的PageRank算法思想,将滑动窗口内的共现词汇对儿当做相连接的节点构建网络,计算节点的价值(即单词的重要性)并排序,数值高的单词即为该文本的关键词。 T…

概述 “文本词向量”节点用于将词和句/段落映射到一个向量,可用来表示词与词之间或句与句之间的关系。该算法基于Skip-gram模型利用词语来预测它的上下文,并表示为向量形式,可应用于社交网络中的推荐系统、文本相似度等场景。 输入 参数 子参…

概述 “词频-逆文档频率”节点主要功能是计算某个词对于所属文档的重要程度。词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)算法规定某个词语的重要性与它在一个文档中出现的次…
