华为云AI开发平台ModelArts文本_云淘科技
TF-IDF 文本词向量 词频统计 文章相似度 字符串相似度 字符串相似度topN NGram Count PMI 关键词抽取 原子分词 文本TF-IDF 三元组转kv 文本分类 LDA 句子拆分 文本摘要 停用词过滤 语义相似距离 父主题…

共18项
TF-IDF 文本词向量 词频统计 文章相似度 字符串相似度 字符串相似度topN NGram Count PMI 关键词抽取 原子分词 文本TF-IDF 三元组转kv 文本分类 LDA 句子拆分 文本摘要 停用词过滤 语义相似距离 父主题…

概述 停用词过滤是自然言语处理中一个重要的步骤。它可以将句子中的噪声词,和一些无关词(通常由用户指定)过滤掉。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的D…

概述 计算距离某个向量最近的k个向量集合。这些向量通常是通过算法生产的包含语义的向量(例如word2vec生产的词向量,或者doc2vec生产的文章向量)。可以用于寻找和一个单词或者一篇文章相似的单词或者文章。 输入 参数 子参数 参数说明…

概述 词频统计是指统计一个字符串中,出现了多少个单词以及这些单词出现的次数。该算子一般接在分词算子后面,用以统计分词后各个单词的出现次数。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,datafr…

概述 支持cosine、levenshtein、jaccard和最长公共子序列四种方法计算文章的相似度。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的Data…

概述 支持cosine、levenshtein、jaccard、最长公共子序列、minhash_sim、ssk、simhash_hamming_sim七种方法计算字符串的相似度。 输入 参数 子参数 参数说明 inputs dataDF i…
概述 支持cosine、levenshtein、jaccard、最长公共子序列、minhash_sim、ssk、simhash_hamming_sim七种方法计算 文章的相似度 输入 参数 子参数 参数说明 inputs dataDF in…

概述 将分词后的句子生成连续N个词的NGram短语,并进行全局个数的统计,支持权重列输入。 输入 参数 子参数 参数说明 inputs input_table 输入表表名,输入的包含分词后的句子的数据表;必填; inputs vocab_t…

概述 承接分词结果,计算一个文档里单词两两之间的互信息值(PMI)。PMI计算公式如下: 相关概念解释: 共现对儿:一句话里面如果两个词在句子里的距离小于等于定义的滑动窗口大小,则这两个词共现形成共现对儿。 P(x,y):x,y为两个词,P…
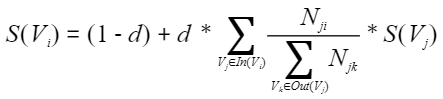
概述 承接分词结果,获取各个文档中的关键词。 原理 该算法基于TextRank,依据的PageRank算法思想,将滑动窗口内的共现词汇对儿当做相连接的节点构建网络,计算节点的价值(即单词的重要性)并排序,数值高的单词即为该文本的关键词。 T…
