华为云AI开发平台ModelArts多层感知机分类(pytorch)_云淘科技

概述 使用pytorch实现的多层感知机分类算法,可运行于异构资源池上。 该算子通过cuda自动判断gpu是否可用。若gpu可用,优先使用gpu训练;否则使用cpu训练。 输入 参数 子参数 参数说明 data_url _ data_url…

共254项
概述 使用pytorch实现的多层感知机分类算法,可运行于异构资源池上。 该算子通过cuda自动判断gpu是否可用。若gpu可用,优先使用gpu训练;否则使用cpu训练。 输入 参数 子参数 参数说明 data_url _ data_url…

概述 LDA主题分析模型(Latent Dirichlet Allocation),由Blei等人于2003年提出的无监督学习算法,可以按照概率分布的形式给出文档集中每篇文档的主题,在文本挖掘领域,应用于文本主题识别、文本分类和文本相似度计…

概述 分层采样是一种数据采样算法,依据数据集中某一代表数据类别的列,按照数量或比例对不同类别的数据进行采样。 算法实现采用spark自带的sample函数,采样数量会存在一定误差(按比例采样和按数量采样均会存在)。 输入 参数 子参数 参数…

概述 用线性模型计算训练数据的特征重要性。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 特征的重要性和特征在线性模型中的we…

概述 使用PyTorch实现的多层感知机分类算法,可运行于异构资源池上。 该算子通过cuda自动判断GPU是否可用。若GPU可用,优先使用GPU训练;否则使用CPU训练。 输入 参数 参数说明 train_url train_url为存储模…

概述 对文本数据按照标点符号进行句子拆分。 该算法按照既定标点符号等进行句子拆分,并将标点符号保留在句末(给定标点符号不单独成行),一篇文章拆分成多行输出。 输入 参数 子参数 参数说明 inputs input_table 输入表表名 输…
概述 “连接”节点是关系数据库中常用的方法之一,用于以特定的方式将两个数据集联接在一起。 输入 参数 子参数 参数说明 inputs left_dataframe inputs为字典类型,left_dataframe为执行连接操作的左数据集…

概述 加权采样是一种数据采样算法,依据数据集中权重列进行数据采样,权重越大的样本被采样的概率越大。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFra…
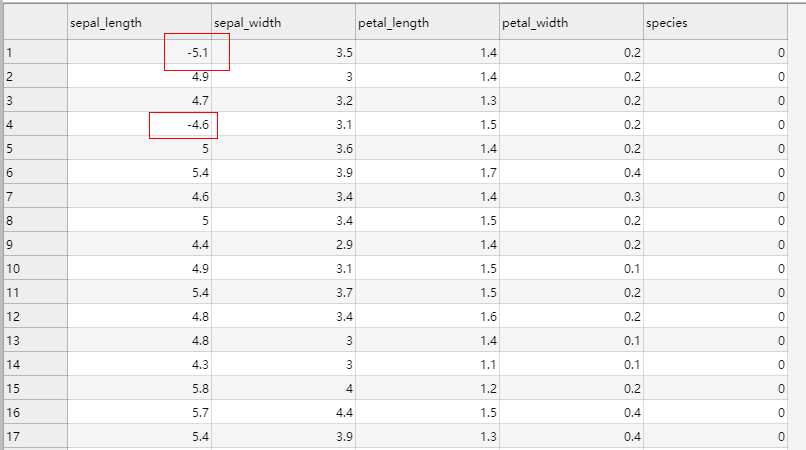
概述 支持对稠密或稀疏的数值类特征进行常见的尺度变换,支持常见的log2、log10、ln、abs及sqrt等尺度变化函数。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pys…

概述 抽取文本中的部分原句作为文本的摘要。 该算法按照既定标点符号等进行句子拆分,基于TextRank思想求出可代表该文档的句子作为其摘要。 输入 参数 子参数 参数说明 inputs input_table 输入表表名 输入参数说明 参数…
