华为云AI开发平台ModelArts安装_云淘科技
安装内置算法 # 安装ivgPose最新版本 > python manage.py install algorithm ivgPose # 安装ivgPose==1.0.0 > python manage.py install …

共254项
安装内置算法 # 安装ivgPose最新版本 > python manage.py install algorithm ivgPose # 安装ivgPose==1.0.0 > python manage.py install …
本小节介绍了基于算法开发套件进行自动化流水线构建的相关参数。目前仅仅支持串行流,以list进行表示,其中的node以dict进行表示,node一般对应于tools中的一个脚本,运行node本质上是直接运行相应脚本。 参数说明 –…
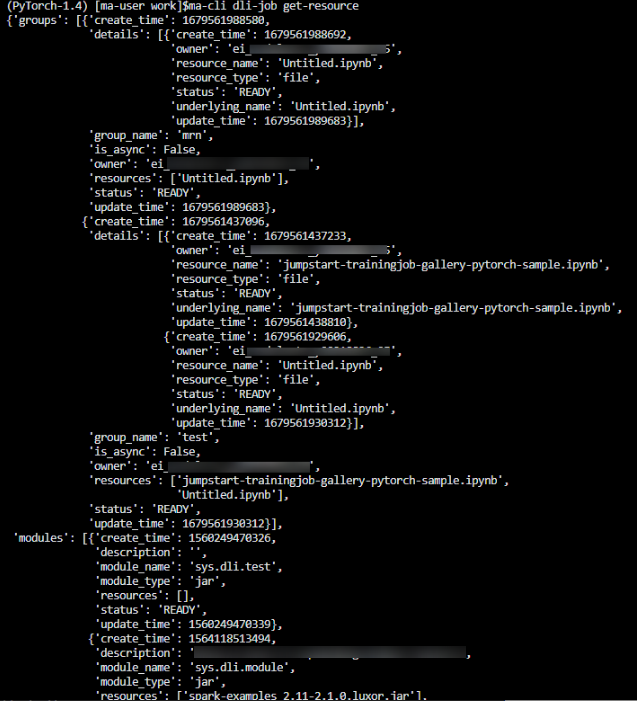
执行ma-cli dli-job get-resource命令获取DLI资源详细信息,如资源名称,资源类型等。 $ ma-cli dli-job get-resource -h Usage: ma-cli dli-job get-resou…
不同存储的实现都不同,在性能、易用性、成本的权衡中可以有不同的选择,没有一个存储可以覆盖所有场景,了解下云上开发环境中各种存储使用场景说明,更能提高使用效率。 表1 云上开发环境中各种存储使用场景说明 存储类型 建议使用场景 优点 缺点 E…
自定义算子代码模板 新建自定义算子时,MLS Editor提供了代码模板,方便用户高效开发算子。 class MLSClassName: # init parameters def __init__(self, inputs, param_…
概述 采用随机森林回归算法计算数据集特征的特征重要性 输入 参数 子参数 参数说明 inputs dataframe 参数必选,表示输入的数据集;如果没有pipeline_model和random_forest_regressor_mode…
概述 按照配置的比例参数,对数据集进行随机抽样。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数据集 参数说明 参数 子参数…
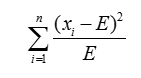
概述 采用卡方检验来进行特征选择。 卡方检验(Chi-Squared Test或χ2 Test)的基本思想是通过特征变量与目标变量之间的偏差大小来选择相关性较大的特征变量。首先假设两个变量是独立的,然后观察实际值与理论值的偏差程度,该偏差程…
概述 将训练出来的spark标准pipeline类型的模型保存到OBS里面 输入 参数 子参数 参数说明 inputs pipeline_model inputs为字典类型,pipeline_model为pyspark中的PipelineM…

概述 二分k-means算法是分层聚类(Hierarchical clustering)的一种,分层聚类是聚类分析中常用的方法。 分层聚类的策略一般有两种: 聚合:这是一种自底向上的方法,每一个观察者初始化本身为一类,然后两两结合。 分裂:…
