华为云云数据库GaussDB审视和修改表定义_云淘科技
审视和修改表定义概述 选择存储模型 选择分布方式 选择分布列 使用局部聚簇 使用分区表 选择数据类型 父主题: SQL调优指南 同意关联代理商云淘科技,购买华为云产品更优惠(QQ 78315851) 内容没看懂? 不太想学习?想快速解决? …

共8项
审视和修改表定义概述 选择存储模型 选择分布方式 选择分布列 使用局部聚簇 使用分区表 选择数据类型 父主题: SQL调优指南 同意关联代理商云淘科技,购买华为云产品更优惠(QQ 78315851) 内容没看懂? 不太想学习?想快速解决? …
进行数据库设计时,表设计上的一些关键项将严重影响后续整库的查询性能。表设计对数据存储也有影响:好的表设计能够减少I/O操作及最小化内存使用,进而提升查询性能。 表的存储模型选择是表定义的第一步。客户业务属性是表的存储模型的决定性因素,依据下…

在分布式框架下,数据分布在各个DN上。一个或者几个DN的数据存在一块物理存储设备上,好的表定义至少需要达到以下几个目标: 表数据均匀分布在各个DN上,以防止单个DN对应的存储设备空间不足造成集群有效容量下降。选择合适分布列,避免数据分布倾斜…
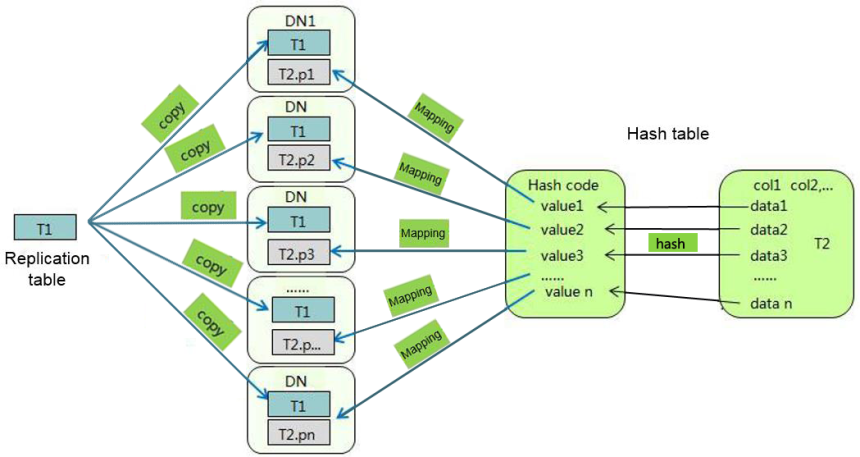
复制表(Replication)方式将表中的全量数据在集群的每一个DN实例上保留一份。主要适用于记录集较小的表。这种存储方式的优点是每个DN上都有该表的全量数据,在join操作中可以避免数据重分布操作,从而减小网络开销,同时减少了plan …
Hash分布表的分布列选取至关重要,需要满足以下原则: 列值应比较离散,以便数据能够均匀分布到各个DN。例如,考虑选择表的主键为分布列,如在人员信息表中选择身份证号码为分布列。 在满足第一条原则的情况下尽量不要选取存在常量filter的列。…
局部聚簇(Partial Cluster Key)是列存下的一种技术。这种技术可以通过min/max稀疏索引较快的实现基表扫描的filter过滤。Partial Cluster Key可以指定多列,但是一般不建议超过2列。Partial C…
分区表是把逻辑上的一张表根据某种方案分成几张物理块进行存储。这张逻辑上的表称之为分区表,物理块称之为分区。分区表是一张逻辑表,不存储数据,数据实际是存储在分区上的。分区表和普通表相比具有以下优点: 改善查询性能:对分区对象的查询可以仅搜索自…
高效数据类型,主要包括以下三方面: 尽量使用执行效率比较高的数据类型 一般来说整型数据运算(包括=、>、<、≧、≦、≠等常规的比较运算,以及group by)的效率比字符串、浮点数要高。比如某客户场景中对列存表进行点查询,filter条件在…
