华为云云数据库GaussDB案例:改写SQL消除in-clause_云淘科技

现象描述 in-clause/any-clause是常见的SQL语句约束条件,有时in或any后面的clause都是常量,类似于: 1 2 3 4 select count(1) from calc_empfyc_c1_result_tmp…

共21项
现象描述 in-clause/any-clause是常见的SQL语句约束条件,有时in或any后面的clause都是常量,类似于: 1 2 3 4 select count(1) from calc_empfyc_c1_result_tmp…

列存表可以选取某一列或几列设置为partial cluster key(column_name[, …])。在导入数据时,按设置的列进行局部排序(默认每70个CU即420万行排序一次),生成的CU会聚集在一起,即CU的min,m…
现象描述 t1的表定义为: 1 create table t1(a int, b int, c int) distribute by hash(a); 假设agg下层算子所输出结果集的分布列为setA,agg操作的group by列为set…
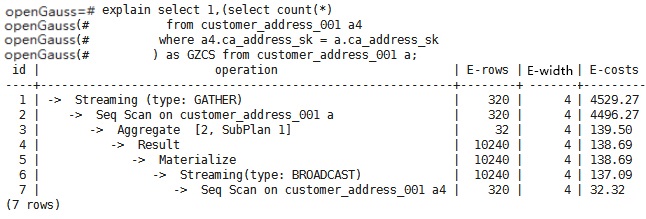
现象描述 1 2 3 4 select 1, (select count(*) from customer_address_001 a4 where a4.ca_address_sk = a.ca_address_sk) as GZCS f…
rewrite_rule包含了多个查询重写规则:magicset、partialpush、uniquecheck、disablerep、intargetlist、predpush等。下面简要说明一下其中重要的几个规则的使用场景: 部分下推参…
DN Gather用来把分布式计划中的Stream节点去掉,而是把数据发送到一个节点进行计算,这样可以减少分布式计划执行时数据重分布的代价,从而提升单个查询以及系统整体的吞吐能力。不过DN Gather面向的是TP的小数据量场景,对于小数据…

调整参数前的参数值: pagewriter_sleep=2000ms bgwriter_delay=2000ms max_io_capacity=500MB 调整参数后的参数值: pagewriter_sleep=100ms bgwrite…
DN Gather用来把分布式计划中的Stream节点去掉,而是把数据发送到一个节点进行计算,这样可以减少分布式计划执行时数据重分布的代价,从而提升单个查询以及系统整体的吞吐能力。不过DN Gather面向的是TP的小数据量场景,对于小数据…

现象描述 某局点EXPLAIN PERFORMANCE信息如下。分析发现如图红框标识的两个性能瓶颈点均为表Scan动作。 优化分析 进一步分析表Scan的filter条件发现两个表存在acct_id = ‘A012709548&…

现象描述 在GaussDB中行存表天然的使用行执行引擎,列存表天然的使用列执行引擎。如果一个SQL语句涉及的表既有行存表又有列存表,系统会自动选择行执行引擎。由于列执行引擎的性能(除indexscan相关的算子)比行执行引擎性能要好很多,因…
