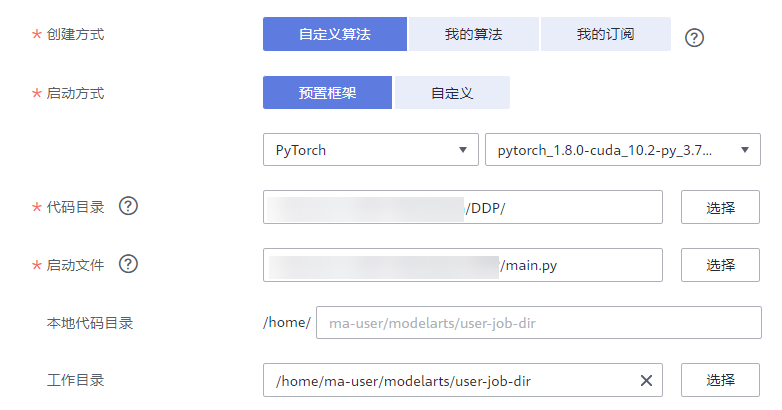
华为云AI开发平台ModelArts多机多卡数据并行-DistributedDataParallel(DDP)_云淘科技
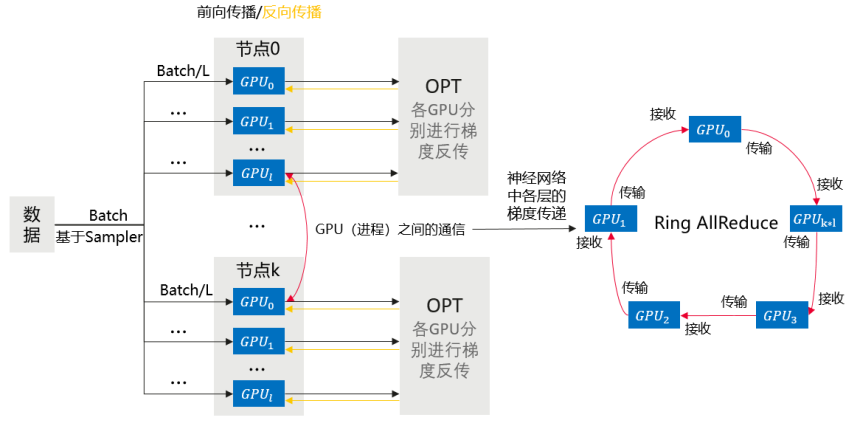
本章节介绍基于Pytorch引擎的多机多卡数据并行训练。 训练流程简述 相比于DP,DDP能够启动多进程进行运算,从而大幅度提升计算资源的利用率。可以基于torch.distributed实现真正的分布式计算,具体的原理此处不再赘述。大致的…