华为云AI开发平台ModelArts向量召回评估_云淘科技

概述 向量召回评估算子计算召回的hitrate,用于评估召回结果的好坏,hitrate越高表示训练产出的向量去召回向量的结果越准确。支持u2i召回和i2i召回的计算。u2i召回时,拿user(用户)的向量去召回top k个items(物品)…

共254项
概述 向量召回评估算子计算召回的hitrate,用于评估召回结果的好坏,hitrate越高表示训练产出的向量去召回向量的结果越准确。支持u2i召回和i2i召回的计算。u2i召回时,拿user(用户)的向量去召回top k个items(物品)…

概述 承接分词结果,计算一个文档里单词两两之间的互信息值(PMI)。PMI计算公式如下: 相关概念解释: 共现对儿:一句话里面如果两个词在句子里的距离小于等于定义的滑动窗口大小,则这两个词共现形成共现对儿。 P(x,y):x,y为两个词,P…

概述 百分位是统计学术语,用于计算数据表列数据的百分位。可以将一组数据从小到大排序,并计算相应数据的百分位,则某百分位所对应数据的值称为该百分位的百分位数。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典…

概述 离散值特征分析通过每个离散特征的gini,entropy,gini gain,information gain,information gain ratio等和每个离散值对应的gini,entropy指标,方便对离散特征进行理解。 输…
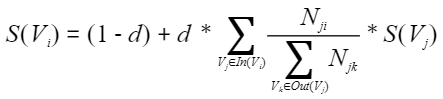
概述 承接分词结果,获取各个文档中的关键词。 原理 该算法基于TextRank,依据的PageRank算法思想,将滑动窗口内的共现词汇对儿当做相连接的节点构建网络,计算节点的价值(即单词的重要性)并排序,数值高的单词即为该文本的关键词。 T…

概述 “协同过滤-Item-based”节点用于推荐场景,它通过用户和物品之间的关系计算物品之间的相似度。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的Dat…

概述 对文本数据进行分词。 该算法基于HanLP,对文本列进行分词,标注词性,并支持识别实体、机构、人名、电话号码、中英文日期、中英文时间,过滤全符号、全英文或全数字结果等,自定义词典或自定义合并的词词性标注为”nz”…

概述 提供的增加序号列组件。您可以在数据表的第一列追加ID列。 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 输出 数据集 参数说明…

概述 读CSV文件支持从LOCAL、OBS、HDFS读取CSV类型的文件数据。 输入 无 输出 表1 参数 子参数 参数说明 output output_port_1 output为字典类型,output_port_1为pyspark中的D…

概述 FM主要是解决稀疏数据下的特征组合问题,并且其预测的复杂度是线性的,对于连续和离散特征有较好的通用性。 公式为: 输入 参数 子参数 参数说明 inputs dataframe inputs为字典类型,dataframe为pyspar…
