
华为云AI开发平台ModelArts关键词抽取_云淘科技
概述
承接分词结果,获取各个文档中的关键词。
原理
该算法基于TextRank,依据的PageRank算法思想,将滑动窗口内的共现词汇对儿当做相连接的节点构建网络,计算节点的价值(即单词的重要性)并排序,数值高的单词即为该文本的关键词。
TextRank公式如下,其中V_i、V_j为网络中的节点(即单词),In(V_i)表示节点V_i的所有入点,Out(V_j)表示节点V_j的全部出点,Out(V_j)表示节点V_j的所有出点(跳转指向的点,即下一个单词),N_ji表示(V_j, V_i)的个数,S(V_i)、S(V_j)表示节点V_i、V_j的价值,d为阻尼系数,默认为0.85。
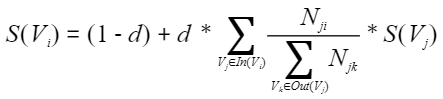
本算法基于pagerank思想,将共现词对儿AB的两条边(A,B)(B,A)添加进网络,相同元素的共现对儿不重复添加,(A,A)自指向共现对儿不添加。
输入
|
参数 |
子参数 |
参数说明 |
|---|---|---|
|
inputs |
input_table |
输入的包含分词后句子的数据表;必填 |
输入参数说明
|
参数名称 |
参数描述 |
参数要求 |
|---|---|---|
|
doc_id_col |
文章id列 |
string类型;必填 |
|
doc_content |
分词后的文本列 |
string类型;必填;多列时每列当做单独的句子处理 |
|
doc_content_sep |
分词列中的词分隔符 |
string类型;必填;默认为” “ |
|
window_size |
滑动窗口大小 |
integer类型;非必填;默认为整行,取值范围[1, 2147483647] |
|
dumping_factor |
TextRank算法的阻尼系数 |
double类型;非必填;默认0.85,取值范围(0, 1) |
|
max_iter |
TextRank算法的最大迭代次数 |
integer类型;非必填;默认100,取值范围[1, 5000] |
|
epsilon |
TextRank算法的收敛残差阈值 |
double类型;非必填;默认0.000001,取值范围(0.000001, 1) |

该算子直接承接分词的结果,无过滤停用词、过滤低频词等操作。
会过滤掉doc_id_col/doc_content为空的行。
输出
|
参数 |
子参数 |
参数说明 |
|---|---|---|
|
output |
output_port_1 |
输出表表名;标签为dataframe |
输出表说明
|
列名 |
列名描述 |
|---|---|
|
docId |
文章id |
|
keywords |
关键词 |
|
weight |
关键词权重 |
样例
数据输入
|
id |
text |
|
1 |
A B C A A A A B D E C B B A A D E C F A F B E |
|
2 |
O O P X O Y O Z Z Z X X Y O X X O Y Y |
|
3 |
O O P X O |
|
4 |
O O P X O Y |
配置流程
运行流程

输入参数

输出结果
|
id |
keywords |
weight |
|
1 |
B |
0.220406 |
|
1 |
A |
0.17985 |
|
1 |
C |
0.17985 |
|
1 |
D |
0.140494 |
|
1 |
E |
0.140494 |
|
2 |
O |
0.277862 |
|
2 |
X |
0.277862 |
|
2 |
P |
0.148092 |
|
2 |
Y |
0.148092 |
|
2 |
Z |
0.148092 |
|
3 |
O |
0.333333 |
|
3 |
P |
0.333333 |
|
3 |
X |
0.333333 |
|
4 |
O |
0.366736 |
|
4 |
P |
0.245928 |
|
4 |
X |
0.245928 |
|
4 |
Y |
0.141408 |
父主题: 文本
同意关联代理商云淘科技,购买华为云产品更优惠(QQ 78315851)
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
