
华为云服务器Spring高手之路16——解析XML配置映射为BeanDefinition的源码_云淘科技
1. BeanDefinition阶段的分析
Spring框架中控制反转(IOC)容器的BeanDefinition阶段的具体步骤,主要涉及到Bean的定义、加载、解析,并在后面进行编程式注入和后置处理。这个阶段是Spring框架中Bean生命周期的早期阶段之一,对于理解整个Spring框架非常关键。
加载配置文件、配置类
在这一步,Spring容器通过配置文件或配置类来了解需要管理哪些Bean。对于基于XML的配置,通常使用ClassPathXmlApplicationContext或者FileSystemXmlApplicationContext。
解析配置文件、配置类并封装为BeanDefinition
Spring框架通过使用BeanDefinitionReader实例(如XmlBeanDefinitionReader)来解析配置文件。解析后,每个Bean配置会被封装成一个BeanDefinition对象,这个对象包含了类名、作用域、生命周期回调等信息。
编程式注入额外的BeanDefinition
除了配置文件定义的Bean,也可以通过编程的方式动态添加BeanDefinition到IOC容器中,这增加了灵活性。
BeanDefinition的后置处理
BeanDefinition的后置处理是指容器允许使用BeanDefinitionRegistryPostProcessor或BeanFactoryPostProcessor来对解析后的BeanDefinition做进一步处理,例如修改Bean的属性等。
2. 加载xml配置文件
2.1 XML配置文件中加载bean的代码示例
先给出最简单的代码示例,然后逐步分析
全部代码如下:
package com.example.demo.bean;
// HelloWorld.java
public class HelloWorld {
private String message;
public void setMessage(String message) {
this.message = message;
}
public void sayHello() {
System.out.println("Hello, " + message + "!");
}
}
主程序:
package com.example.demo;
import com.example.demo.bean.HelloWorld;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class DemoApplication {
public static void main(String[] args) {
// 创建Spring上下文(容器)
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("ApplicationContext.xml");
// 从容器中获取bean,假设我们有一个名为 'helloWorld' 的bean
HelloWorld helloWorld = context.getBean("helloWorld", HelloWorld.class);
// 使用bean
helloWorld.sayHello();
// 关闭上下文
context.close();
}
}
xml文件
运行结果:
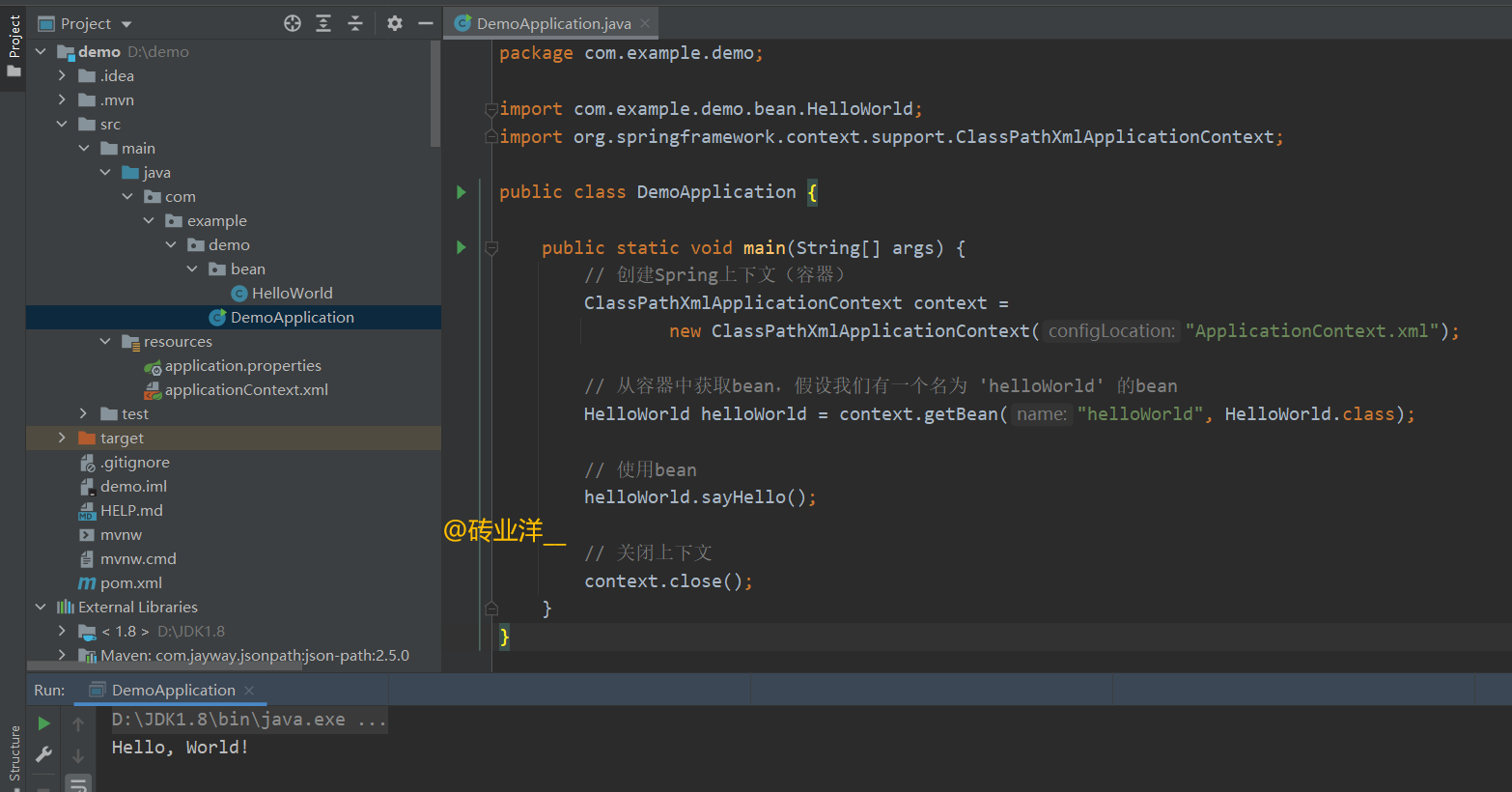
接着我们就从这段代码开始分析
2.2 setConfigLocations – 设置和保存配置文件路径
我们还是以Spring 5.3.7的源码为例分析
// 创建Spring上下文(容器)
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("ApplicationContext.xml");
这段代码,我们利用idea点击去分析,最后在ClassPathXmlApplicationContext的重载方法里看到调用了setConfigLocations设置配置文件的路径。
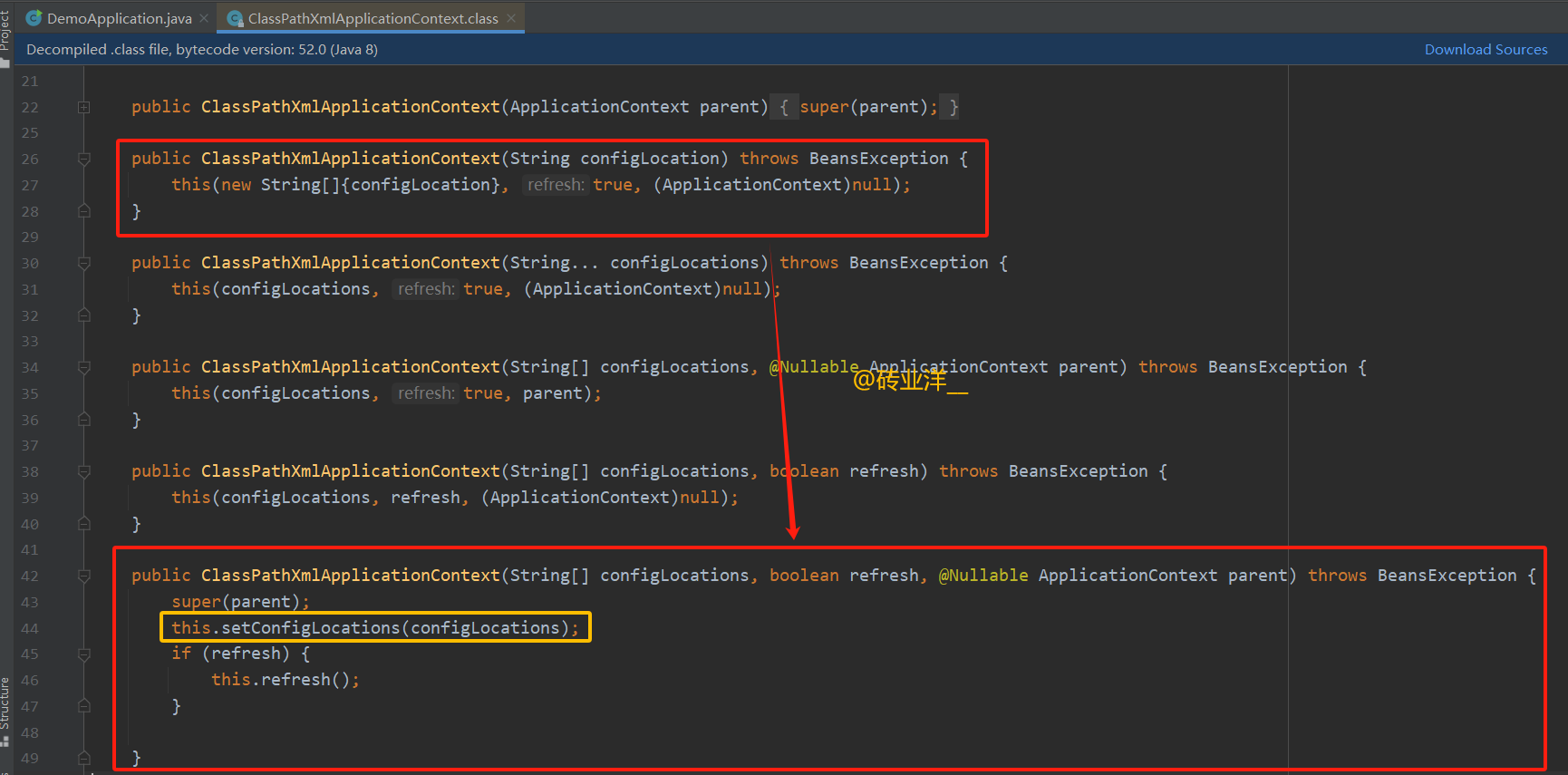
接着看看setConfigLocations方法
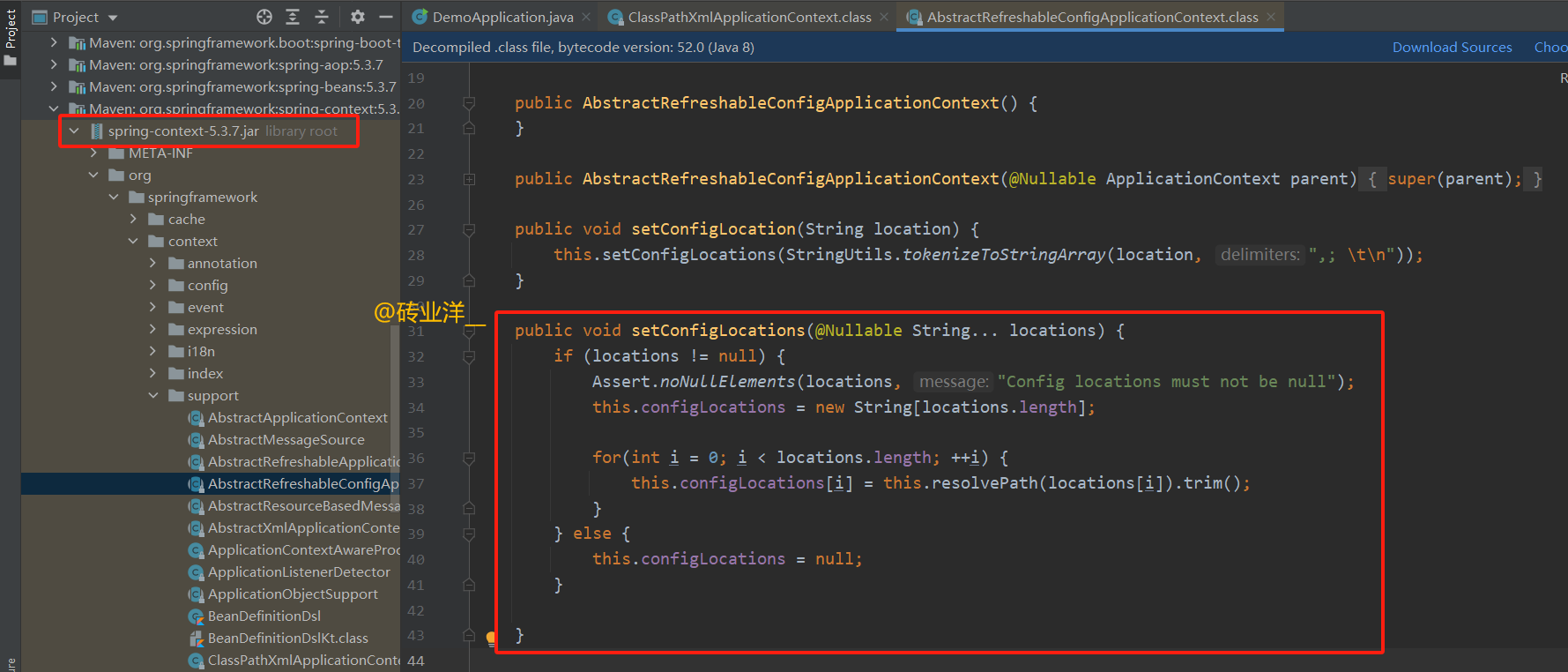
setConfigLocations() 方法的主要作用是设定 Spring 容器加载 Bean 定义时所需要读取的配置文件路径。这些路径可以是类路径下的资源、文件系统中的资源或者其他任何通过URL定位的资源。该方法确保所有提供的配置路径都被保存并在稍后的容器刷新操作中使用。
源码提出来分析:
public void setConfigLocations(@Nullable String... locations) {
if (locations != null) {
// 使用Spring的Assert类来校验,确保传入的配置位置数组中没有null元素。
Assert.noNullElements(locations, "Config locations must not be null");
// 根据传入的配置位置数量,初始化内部存储配置位置的数组。
this.configLocations = new String[locations.length];
// 遍历传入的配置位置数组。
for(int i = 0; i < locations.length; ++i) {
// 调用resolvePath方法处理每一个配置位置(可能进行必要的路径解析,如解析占位符)。
// trim()用于移除字符串首尾的空格,保证保存的路径是净化的。
this.configLocations[i] = this.resolvePath(locations[i]).trim();
}
} else {
// 如果传入的配置位置是null,清除掉所有已设定的配置位置。
this.configLocations = null;
}
}
在上下文被刷新的时候,这些配置文件位置会被读取,并且Spring容器将解析其中定义的beans并将它们注册到容器中。setConfigLocations() 方法只是设置了这些位置,而实际的加载和注册过程是在上下文刷新时完成的。
这个setConfigLocations方法通常不是由用户直接调用的,而是在ApplicationContext初始化的过程中被框架调用,例如在基于XML的配置中,我们会在初始化ClassPathXmlApplicationContext或FileSystemXmlApplicationContext时提供配置文件的路径。
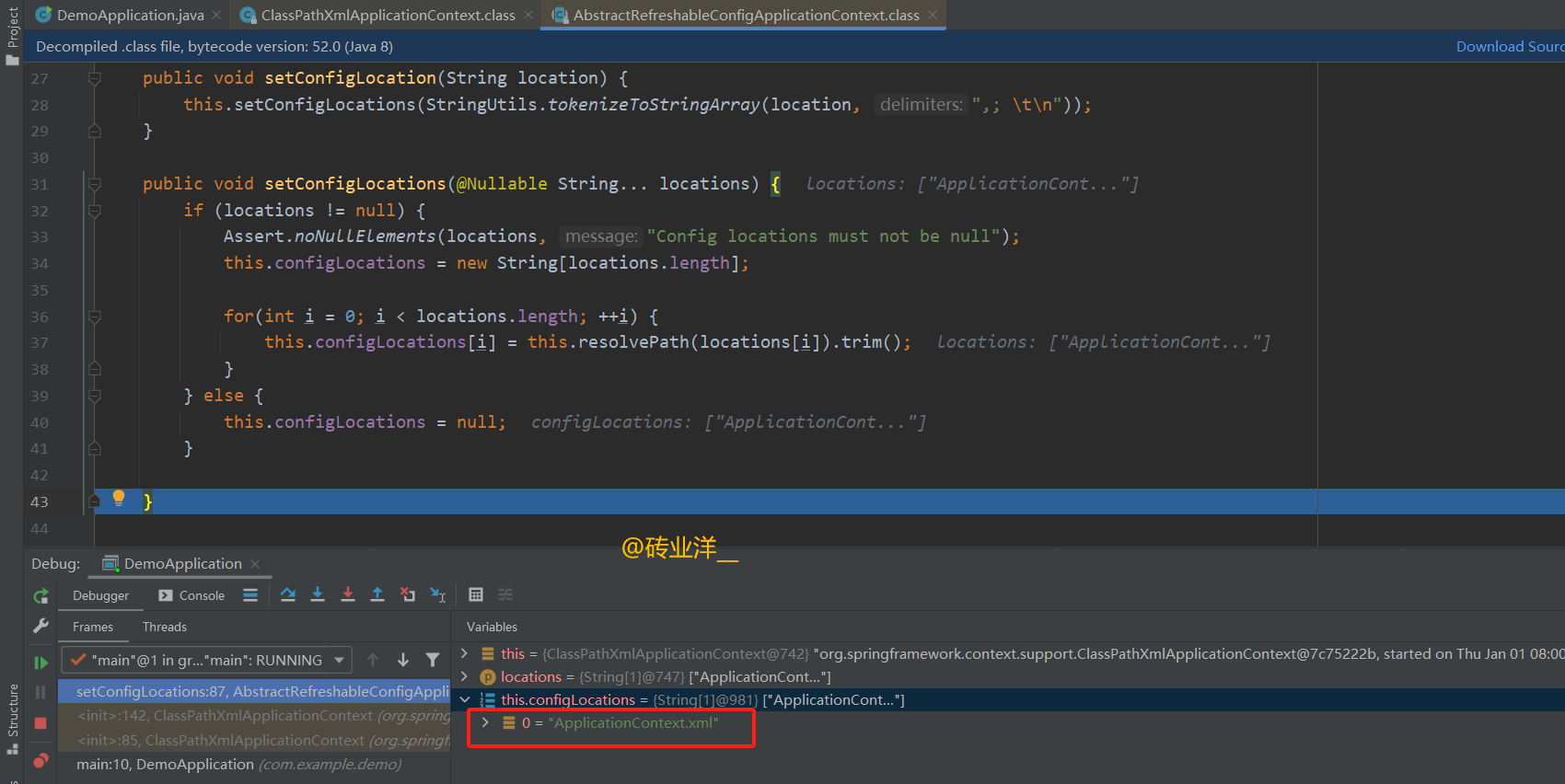
在debug的时候,可以看到把测试代码中设置的 xml 配置文件的路径保存了。
2.3 refresh – 触发容器刷新,配置文件的加载与解析
我们上面看到ClassPathXmlApplicationContext方法里面,执行完setConfigLocations后,紧接着有个refresh方法,我们来看看。
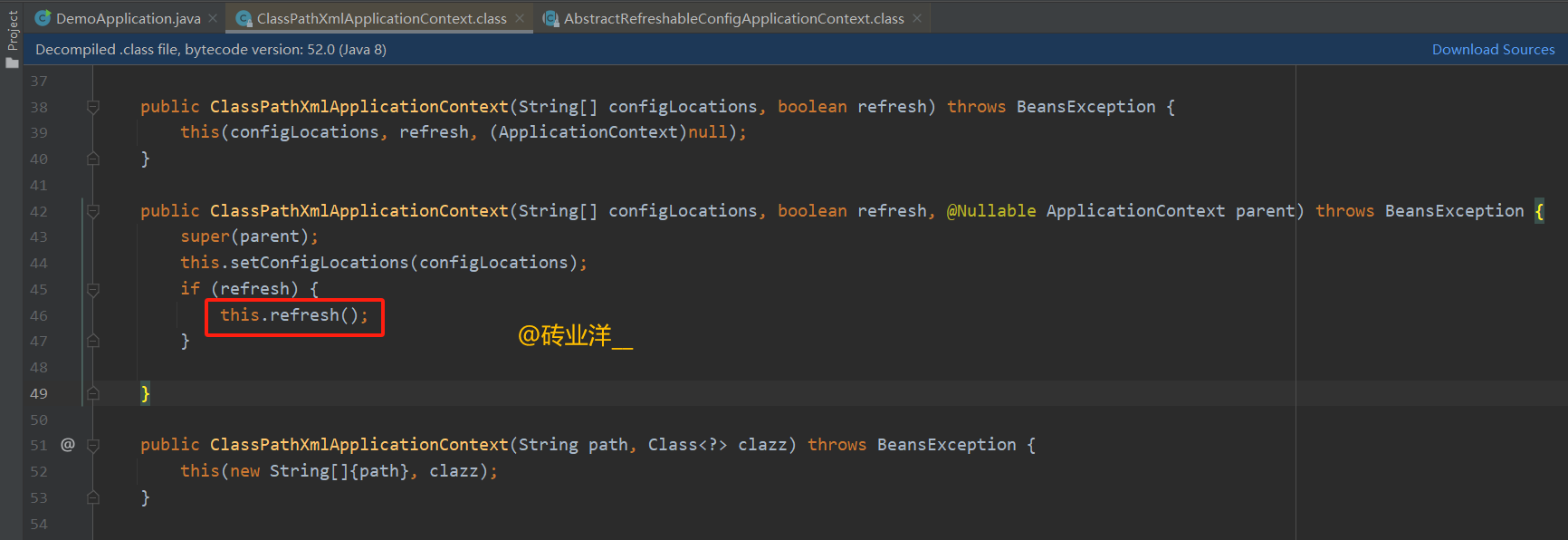
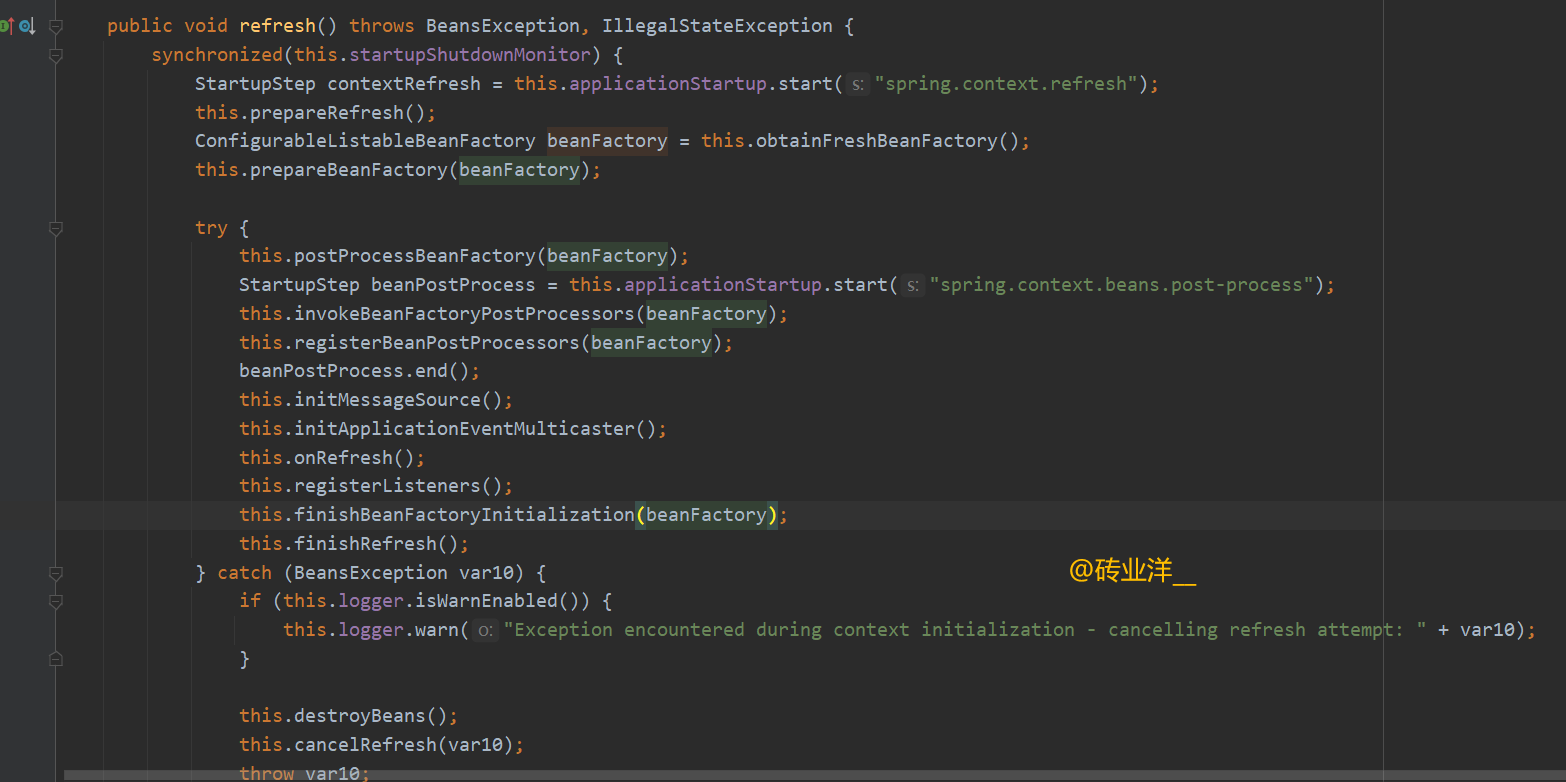
在Spring框架中,refresh()方法是非常关键的,它是ApplicationContext接口的一部分。这个方法的主要功能是刷新应用上下文,加载或者重新加载配置文件中定义的Bean,初始化所有的单例,配置消息资源,事件发布器等。
代码提出来分析:
public void refresh() throws BeansException, IllegalStateException {
// 同步块,确保容器刷新过程的线程安全
synchronized(this.startupShutdownMonitor) {
// 开始上下文刷新的步骤记录,用于监控和诊断
StartupStep contextRefresh = this.applicationStartup.start("spring.context.refresh");
// 准备刷新过程,设置开始时间,状态标志等
this.prepareRefresh();
// 获取新的BeanFactory,如果是第一次刷新则创建一个BeanFactory
ConfigurableListableBeanFactory beanFactory = this.obtainFreshBeanFactory();
// 配置BeanFactory,注册忽略的依赖接口等
this.prepareBeanFactory(beanFactory);
try {
// 允许BeanFactory的后置处理器对其进行修改
this.postProcessBeanFactory(beanFactory);
// 开始Bean工厂的后置处理步骤的监控
StartupStep beanPostProcess = this.applicationStartup.start("spring.context.beans.post-process");
// 调用BeanFactoryPostProcessors
this.invokeBeanFactoryPostProcessors(beanFactory);
// 注册BeanPostProcessors到BeanFactory
this.registerBeanPostProcessors(beanFactory);
// Bean后置处理步骤结束
beanPostProcess.end();
// 初始化MessageSource组件,用于国际化等功能
this.initMessageSource();
// 初始化事件广播器
this.initApplicationEventMulticaster();
// 留给子类覆盖的定制方法
this.onRefresh();
// 注册监听器
this.registerListeners();
// 初始化剩余的单例Bean
this.finishBeanFactoryInitialization(beanFactory);
// 完成刷新过程,通知生命周期处理器lifecycleProcessor刷新过程,发布ContextRefreshedEvent事件
this.finishRefresh();
} catch (BeansException var10) {
// 捕获BeansException,记录警告信息,销毁已创建的Bean
if (this.logger.isWarnEnabled()) {
this.logger.warn("Exception encountered during context initialization - cancelling refresh attempt: " + var10);
}
// 销毁已经初始化的单例Bean
this.destroyBeans();
// 取消刷新,重置同步监视器上的标志位
this.cancelRefresh(var10);
// 抛出异常,结束刷新过程
throw var10;
} finally {
// 在刷新的最后,重置Spring内核中的共享缓存
this.resetCommonCaches();
// 结束上下文刷新步骤的记录
contextRefresh.end();
}
}
}
这个方法精确执行一系列步骤来配置ApplicationContext,包括Bean的加载、注册和初始化。刷新过程包括了Bean定义的载入、注册以及Bean的初始化等一系列复杂的步骤。
在现代Spring框架中,ApplicationContext一般在容器启动时刷新一次。一旦容器启动并且上下文被刷新,所有的Bean就被加载并且创建了。尽管技术上可能存在调用refresh()方法多次的可能性,但这在实际中并不常见,因为这意味着重置应用上下文的状态并重新开始。这样做将销毁所有的单例Bean,并重新初始化它们,这在大多数应用中是不可取的,不仅代价昂贵而且可能导致状态丢失、数据不一致等问题。
对于基于xml的ApplicationContext(如ClassPathXmlApplicationContext),在调用refresh()方法时会重新读取和解析配置文件,然后重新创建BeanFactory和Bean的定义。如果容器已经被刷新过,则需要先销毁所有的单例Bean,关闭BeanFactory,然后重新创建。通常,这个功能用于开发过程中或者测试中,不推荐在生产环境使用,因为它的开销和风险都很大。
我们来看一下重点,加载配置文件的操作在哪里?这里图上我标注出来了,obtainFreshBeanFactory方法里面有个refreshBeanFactory方法。
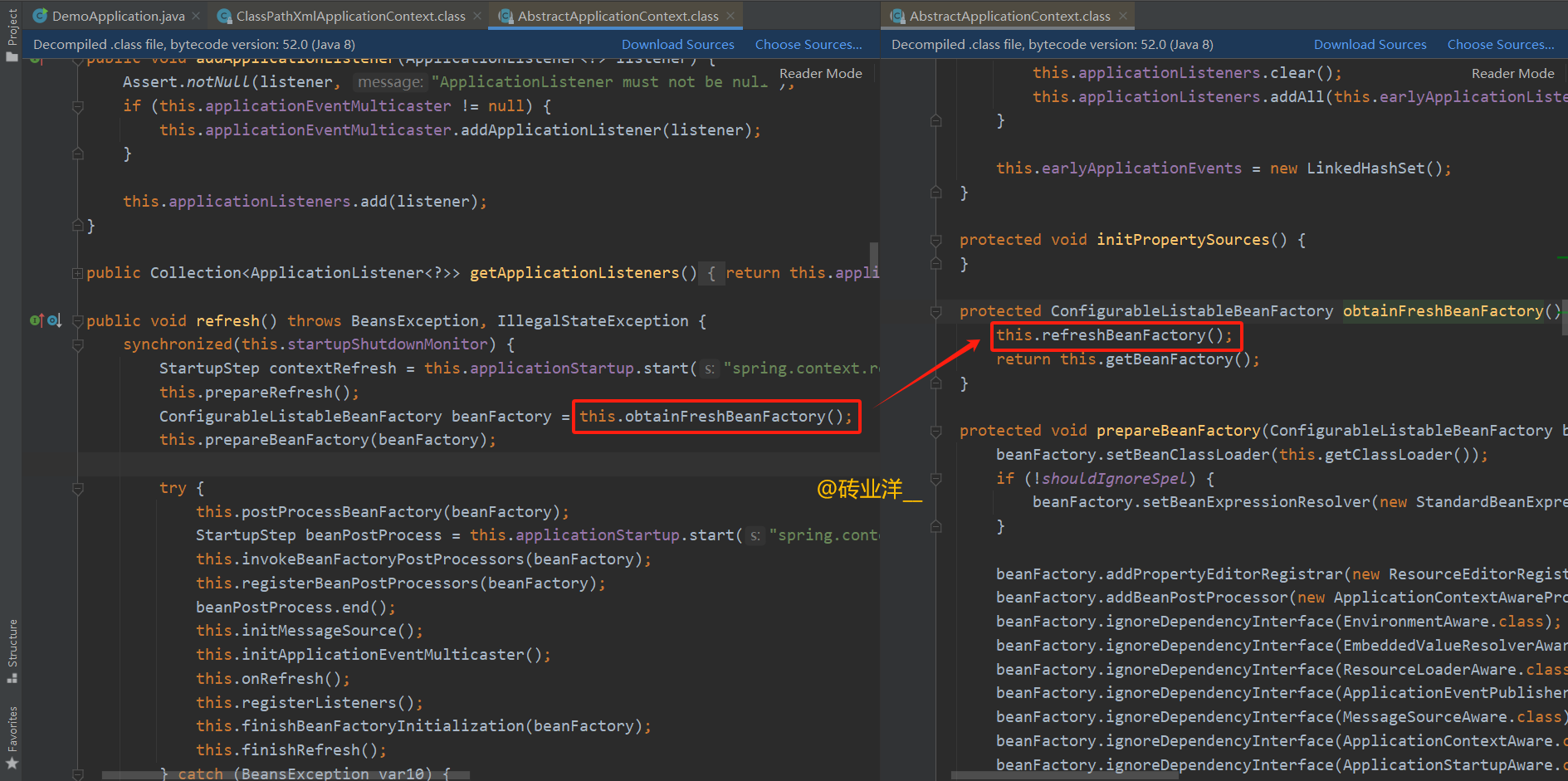
refreshBeanFactory方法是个抽象方法,我们来看看实现类是怎么实现的,根据继承关系找到实现类的refreshBeanFactory方法。
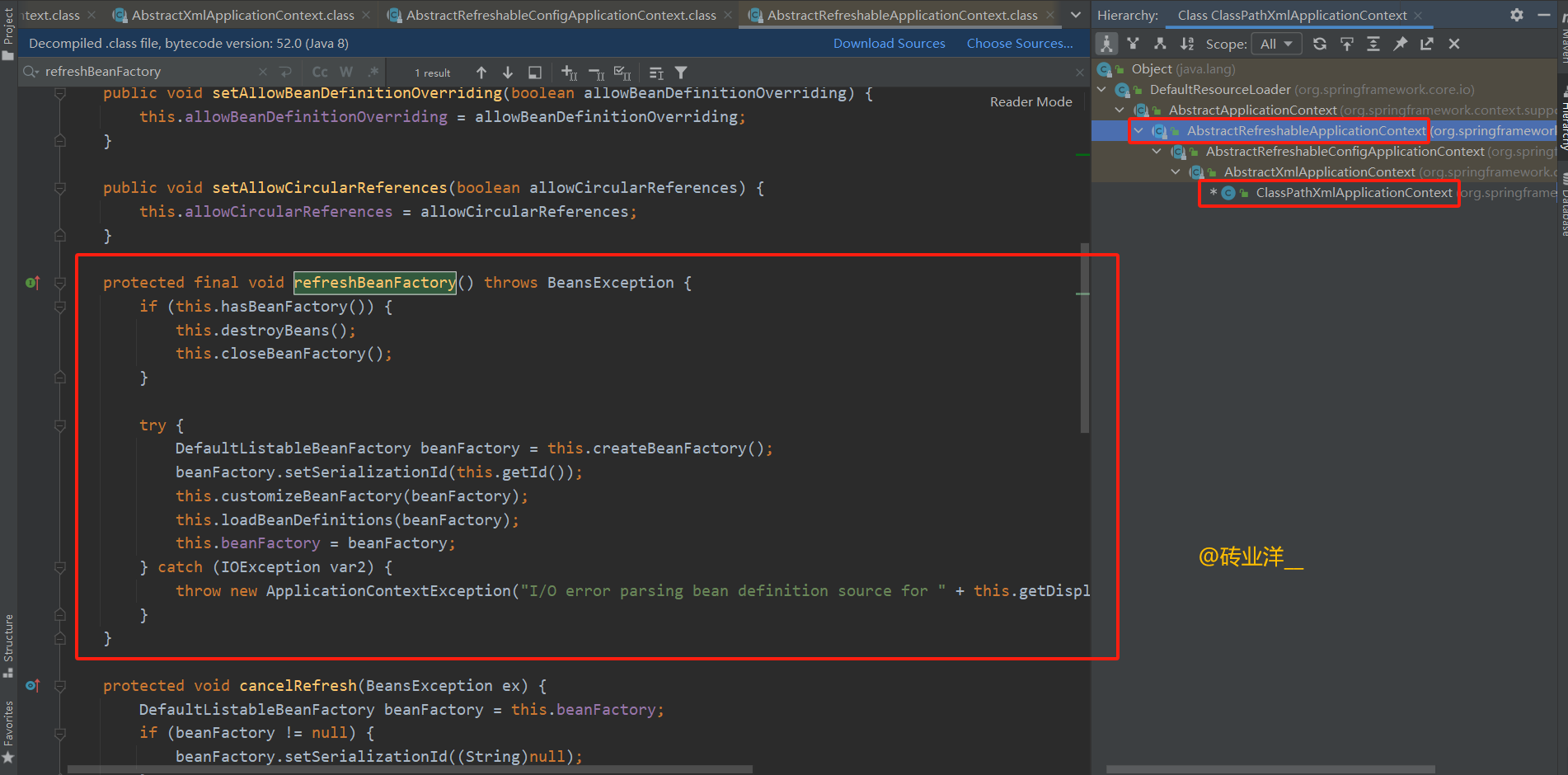
refreshBeanFactory()方法通常在refresh()方法中被调用。这个方法确保当前ApplicationContext含有一个清洁状态的BeanFactory。
代码提出来分析:
protected final void refreshBeanFactory() throws BeansException {
// 检查当前应用上下文是否已经包含了一个BeanFactory
if (this.hasBeanFactory()) {
// 如果已经存在BeanFactory,销毁它管理的所有bean
this.destroyBeans();
// 关闭现有的BeanFactory,释放其可能持有的任何资源
this.closeBeanFactory();
}
try {
// 创建一个DefaultListableBeanFactory的新实例,这是Spring中ConfigurableListableBeanFactory接口的默认实现
DefaultListableBeanFactory beanFactory = this.createBeanFactory();
// 为beanFactory设置一个序列化ID,这个ID后面可以用于反序列化
beanFactory.setSerializationId(this.getId());
// 允许子类定制新创建的beanFactory
this.customizeBeanFactory(beanFactory);
// 从底层资源(例如XML文件)中加载bean定义到beanFactory
this.loadBeanDefinitions(beanFactory);
// 将新的beanFactory赋值给这个上下文的beanFactory属性
this.beanFactory = beanFactory;
} catch (IOException var2) {
// 如果在解析bean定义资源过程中发生I/O异常,将其包装并重新抛出为ApplicationContextException
throw new ApplicationContextException("I/O错误解析用于" + this.getDisplayName() + "的bean定义源", var2);
}
}
这个方法在AbstractApplicationContext的具体实现中被重写。它提供了刷新bean工厂的模板——如果已经存在一个,则将其销毁并关闭;然后创建一个新的bean工厂,进行定制,并填充bean定义。在加载bean定义(例如,从XML文件读取)时,如果遇到I/O异常,会抛出一个ApplicationContextException,提供有关错误性质的更多上下文信息。
这段代码我们可以看到有loadBeanDefinitions方法,是从底层资源(例如XML文件)中加载bean定义到beanFactory,逻辑很复杂,我们下面来进行单独分析。
2.4 loadBeanDefinitions – 具体的BeanDefinition加载逻辑
this.loadBeanDefinitions 方法是在 AbstractApplicationContext 的子类中实现的,这种模式是一个典型的模板方法设计模式的例子。在模板方法设计模式中,一个算法的框架(即一系列的步骤)被定义在父类的方法中,但是一些步骤的具体实现会延迟到子类中完成。
AbstractApplicationContext 提供了 refreshBeanFactory 方法的框架,这个方法定义了刷新 BeanFactory 的步骤,但是它将 loadBeanDefinitions 的具体实现留给了子类。子类需要根据具体的存储资源类型(比如 XML 文件、Java 注解、Groovy 脚本等)来实现这个方法。
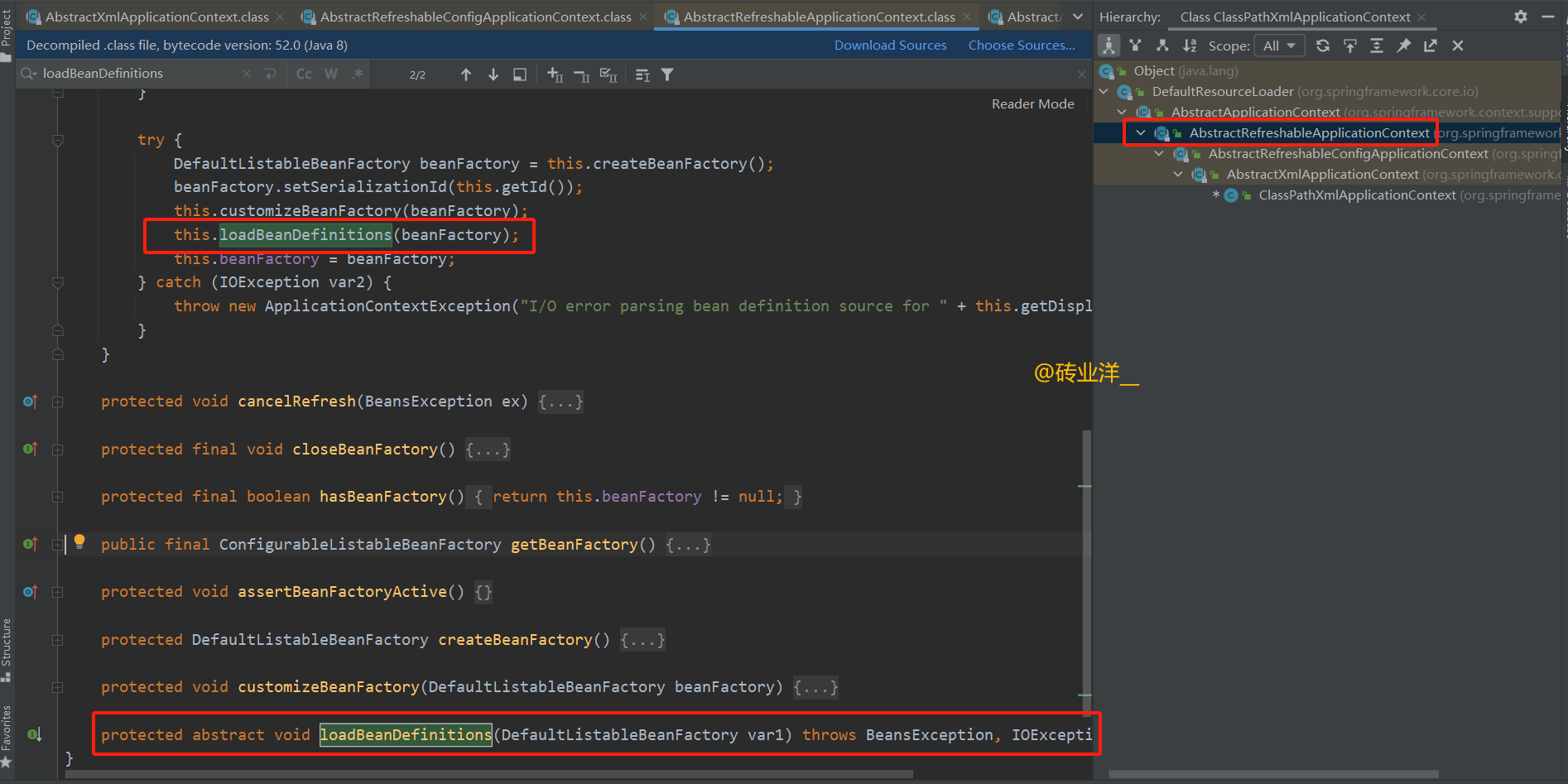
子类AbstractXmlApplicationContext实现的loadBeanDefinitions 方法如下:
loadBeanDefinitions()方法是Spring框架中用于加载、解析并注册Bean定义的核心方法。其基本职责是从一个或多个源读取配置信息,然后将这些信息转换成Spring容器可以管理的Bean定义。这个方法通常在Spring上下文初始化过程中被调用,是Spring容器装载Bean定义的关键步骤。
代码提出来分析:
// 使用DefaultListableBeanFactory作为Bean定义注册的目标工厂,加载Bean定义
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// 创建一个读取XML Bean定义的读取器,并将工厂传入用于注册定义
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 设置环境对象,可能包含属性解析相关的环境配置
beanDefinitionReader.setEnvironment(this.getEnvironment());
// 设置资源加载器,允许读取器加载XML资源
beanDefinitionReader.setResourceLoader(this);
// 设置实体解析器,用于解析XML中的实体如DTD
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// 初始化Bean定义读取器,可能设置一些参数,如是否验证XML
this.initBeanDefinitionReader(beanDefinitionReader);
// 调用重载的loadBeanDefinitions,根据配置的资源和位置加载Bean定义
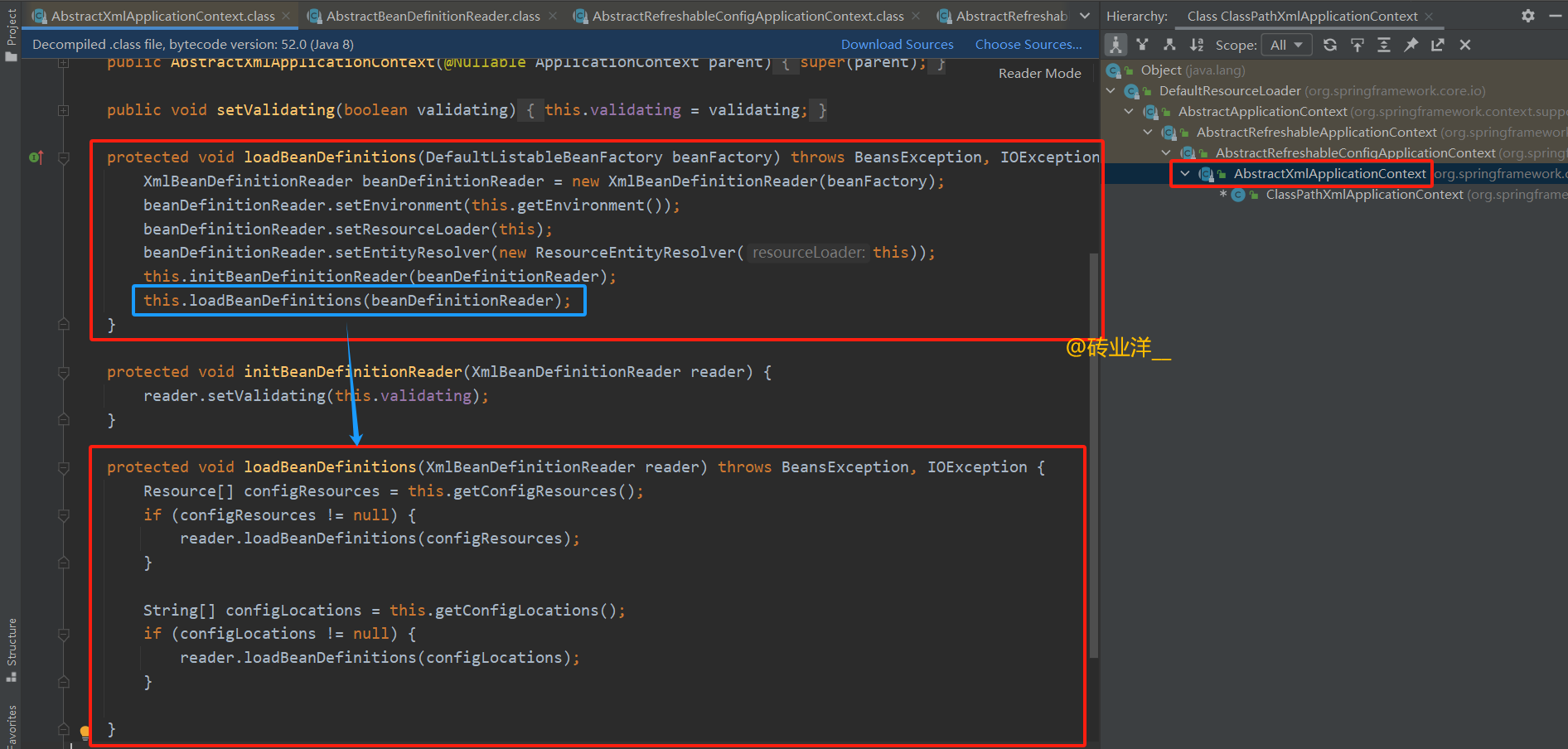
this.loadBeanDefinitions(beanDefinitionReader);
}
// 初始化Bean定义读取器,主要设置是否进行XML验证
protected void initBeanDefinitionReader(XmlBeanDefinitionReader reader) {
// 设置XML验证模式,通常取决于应用上下文的配置
reader.setValidating(this.validating);
}
// 通过XmlBeanDefinitionReader加载Bean定义
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
// 获取所有配置资源的数组(如XML配置文件)
Resource[] configResources = this.getConfigResources();
// 如果配置资源非空,则加载这些资源
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
// 获取所有配置文件位置的数组
String[] configLocations = this.getConfigLocations();
// 如果配置文件位置非空,则加载这些位置指定的配置文件
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
在loadBeanDefinitions(DefaultListableBeanFactory beanFactory)方法中,首先创建了一个XmlBeanDefinitionReader实例,这个读取器是专门用来解析XML配置文件并把Bean定义加载到DefaultListableBeanFactory中。beanDefinitionReader的相关属性被设置了,包括环境变量、资源加载器和实体解析器。这些设置确保了beanDefinitionReader能正确地解析XML文件并能解析文件中的占位符和外部资源。
接着,通过调用initBeanDefinitionReader方法,可以对XmlBeanDefinitionReader实例进行一些额外的配置,例如设置XML验证。最后,调用loadBeanDefinitions(XmlBeanDefinitionReader reader)方法实际进行加载操作。这个方法会调用读取器来实际地读取和解析XML文件,把Bean定义加载到Spring容器中。
在loadBeanDefinitions(XmlBeanDefinitionReader reader)方法中,首先尝试从getConfigResources方法获取XML配置文件资源,如果存在这样的资源,则通过reader加载这些定义。其次,尝试获取配置文件位置信息,如果存在,则通过reader加载这些位置指定的配置文件。这种设计允许从不同的来源加载配置,如直接从资源文件或者从指定的文件路径。
debug可以看到reader和configLocations的详细状态
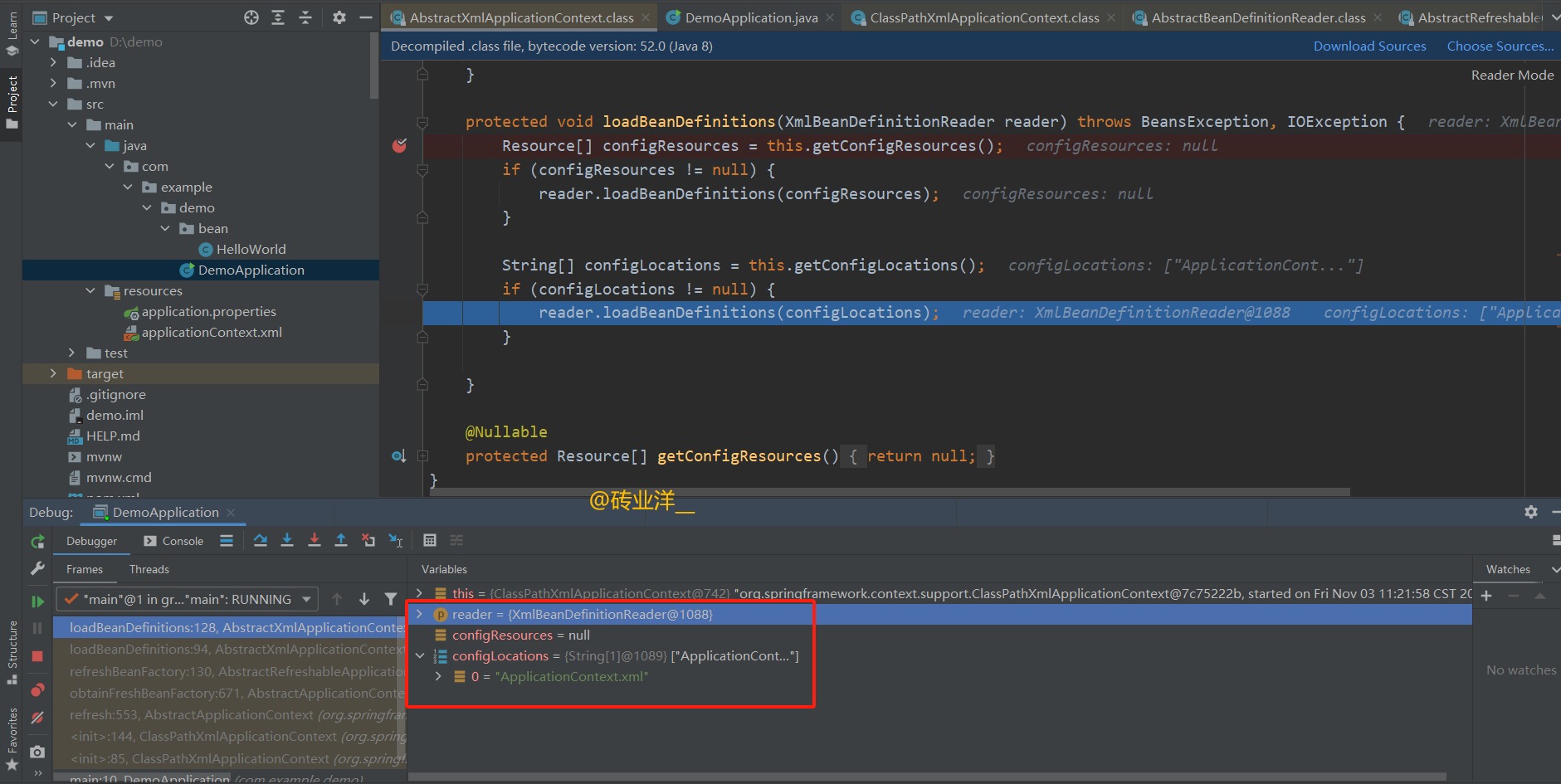
这里看到还有一个reader.loadBeanDefinitions(configLocations);这是在做什么呢?下面接着来看!
2.5 loadBeanDefinitions – 由XmlBeanDefinitionReader实现
debug的时候可以看到这里的reader是XmlBeanDefinitionReader,点击跟踪reader.loadBeanDefinitions(configLocations);方法,调用的方法在AbstractBeanDefinitionReader,而XmlBeanDefinitionReader 继承自 AbstractBeanDefinitionReader。
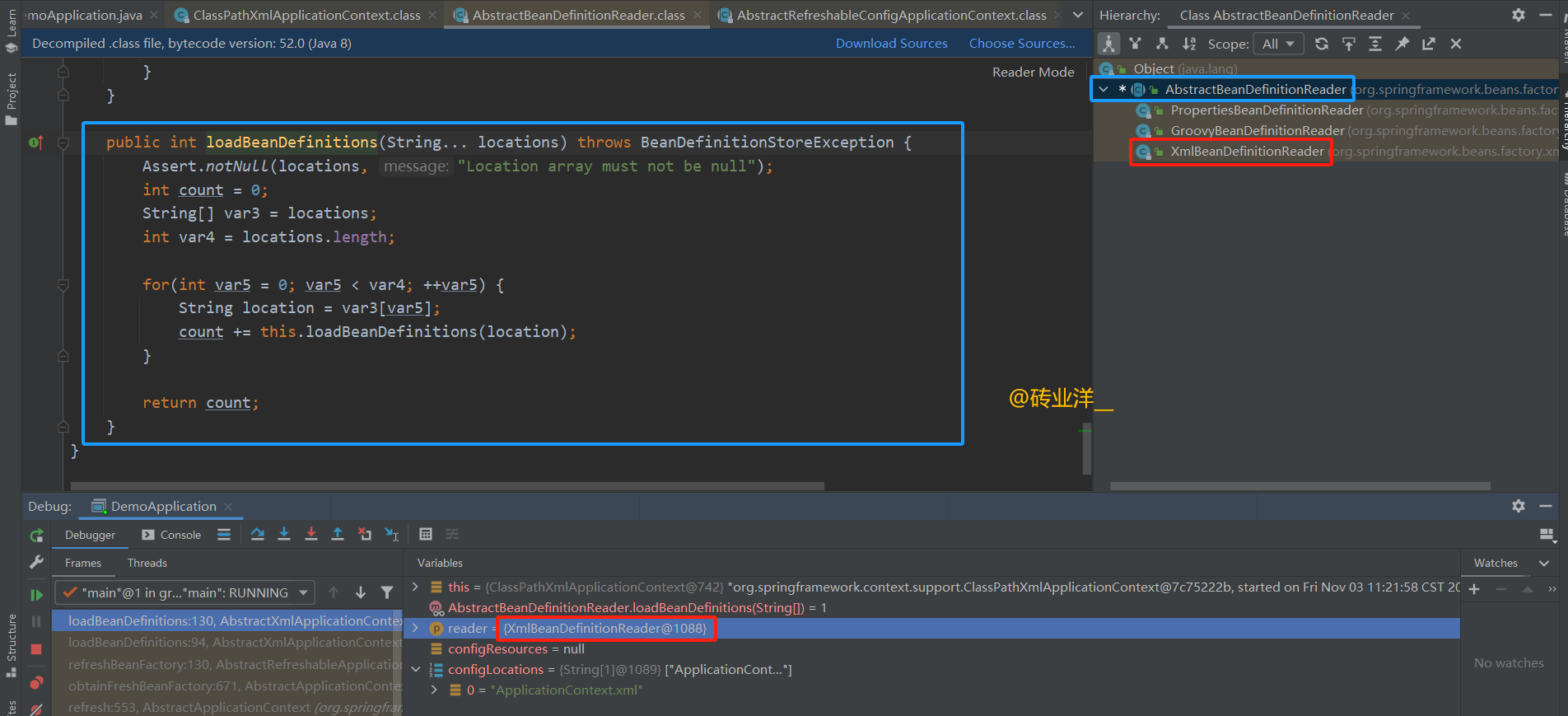
这里配置文件循环加载,有一个count += this.loadBeanDefinitions(location); 继续跟踪!
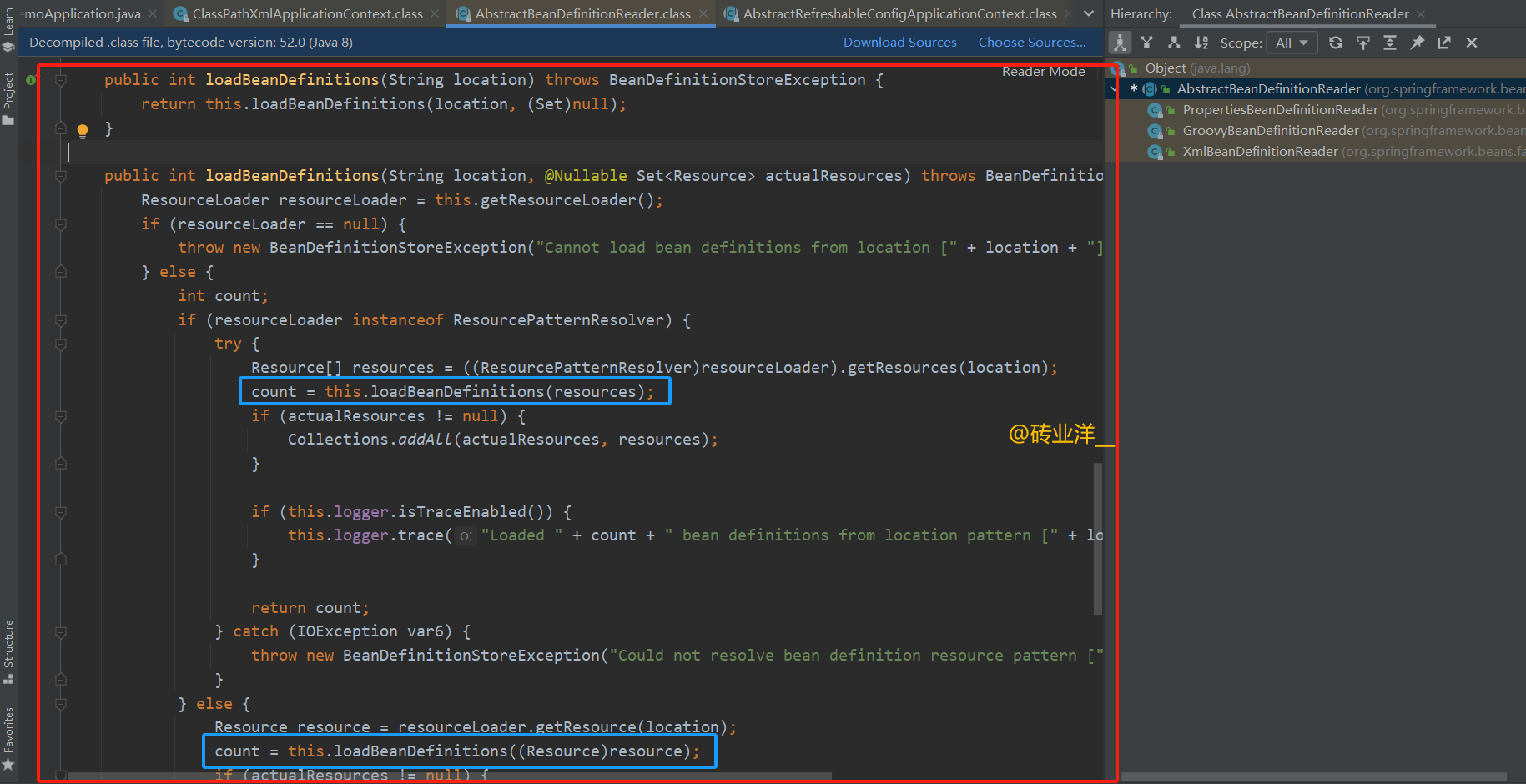
这段代码的逻辑动作大致为:
根据传入的资源位置字符串,通过资源加载器(ResourceLoader)获取对应的资源。
如果资源加载器是资源模式解析器(ResourcePatternResolver),它会处理路径中的模式(比如通配符),加载所有匹配的资源。
读取资源,解析并注册其中定义的所有bean定义。
如果提供了一个实际资源的集合(actualResources),解析出来的资源将被添加到这个集合中。
返回加载并注册的bean定义的数量。
我们还是看重点,继续跟踪里面的loadBeanDefinitions
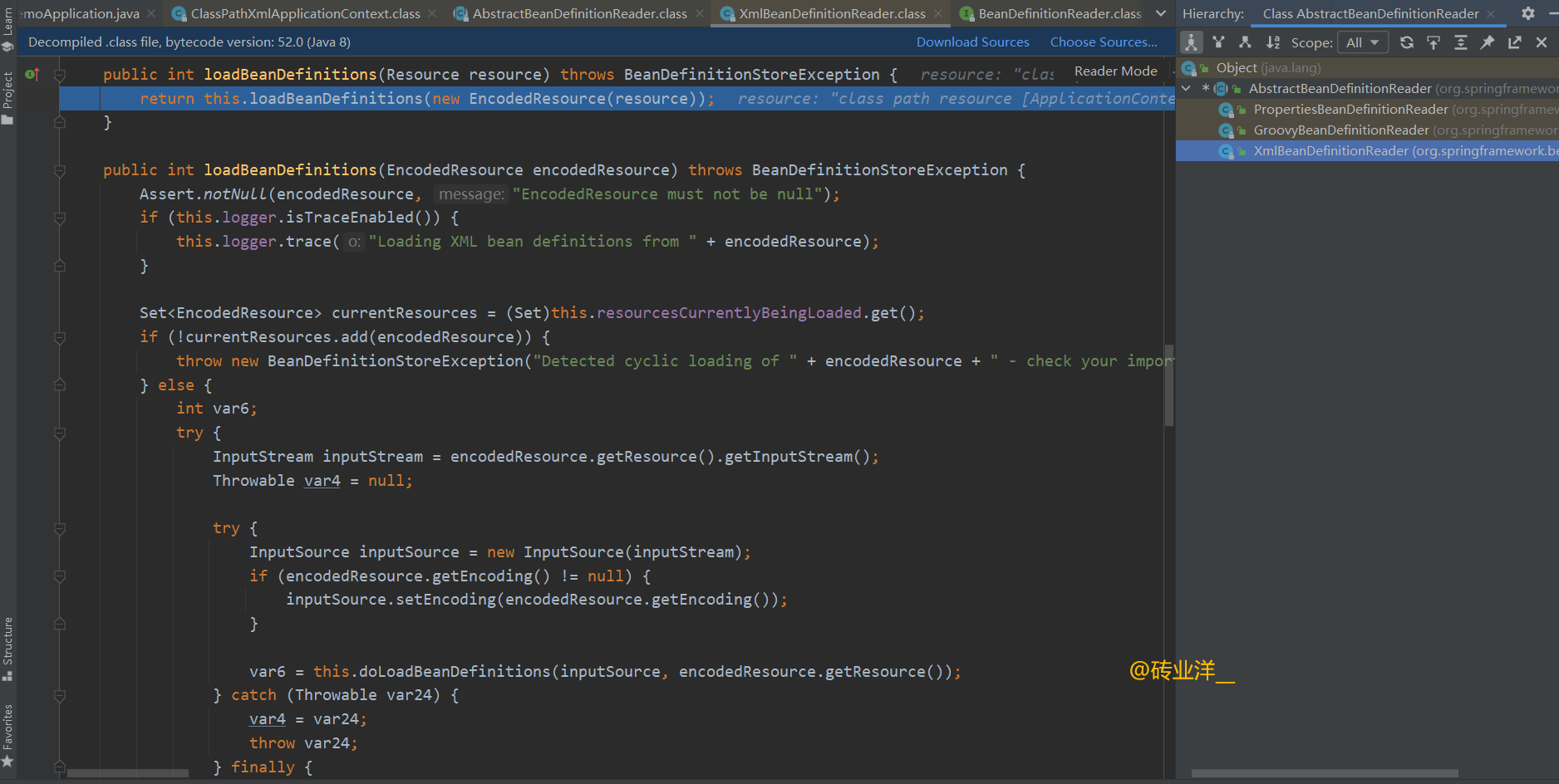
代码提出来分析:
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
// 将Resource包装为EncodedResource,允许指定编码,然后继续加载Bean定义
return this.loadBeanDefinitions(new EncodedResource(resource));
}
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
// 断言传入的EncodedResource不为空
Assert.notNull(encodedResource, "EncodedResource must not be null");
// 如果日志级别为trace,则输出跟踪日志
if (this.logger.isTraceEnabled()) {
this.logger.trace("Loading XML bean definitions from " + encodedResource);
}
// 获取当前线程正在加载的资源集合
Set currentResources = (Set)this.resourcesCurrentlyBeingLoaded.get();
// 检查资源是否已经在加载中,如果是,则抛出BeanDefinitionStoreException异常,避免循环加载
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException("Detected cyclic loading of " + encodedResource + " - check your import definitions!");
} else {
int var6; // 这将用来存储加载的Bean定义数量
try {
// 打开资源的InputStream进行读取
InputStream inputStream = encodedResource.getResource().getInputStream();
Throwable var4 = null;
try {
// 将InputStream封装为InputSource,XML解析器可以接受这个类型
InputSource inputSource = new InputSource(inputStream);
// 如果资源编码不为空,设置资源的编码
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 实际加载Bean定义的方法,返回加载的Bean定义数量
var6 = this.doLoadBeanDefinitions(inputSource, encodedResource.getResource());
} catch (Throwable var24) {
// 捕获Throwable以便在finally块中处理资源释放
var4 = var24;
throw var24;
} finally {
// 关闭InputStream资源
if (inputStream != null) {
if (var4 != null) {
try {
inputStream.close();
} catch (Throwable var23) {
// 添加被抑制的异常
var4.addSuppressed(var23);
}
} else {
inputStream.close();
}
}
}
} catch (IOException var26) {
// 抛出IOException异常,如果解析XML文档失败
throw new BeanDefinitionStoreException("IOException parsing XML document from " + encodedResource.getResource(), var26);
} finally {
// 从当前加载的资源集合中移除该资源
currentResources.remove(encodedResource);
// 如果当前加载的资源集合为空,则从ThreadLocal中移除
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
// 返回加载的Bean定义数量
return var6;
}
}
在这段代码中,loadBeanDefinitions 首先将Resource转换为EncodedResource,这允许它保留关于资源编码的信息。然后,它尝试将资源加载为InputStream并将其转换为InputSource,这是XML解析所需要的。接着它调用doLoadBeanDefinitions方法,实际上负责解析XML并注册Bean定义。
在这个过程中,代码确保了不会循环加载相同的资源,并且在加载资源时,如果发生异常,会适当地清理资源并报告错误。加载的Bean定义数量在完成后被返回。
我们来重点看下这段代码的重点步骤:doLoadBeanDefinitions方法!
2.6 doLoadBeanDefinitions – 读取并解析XML配置文件内容
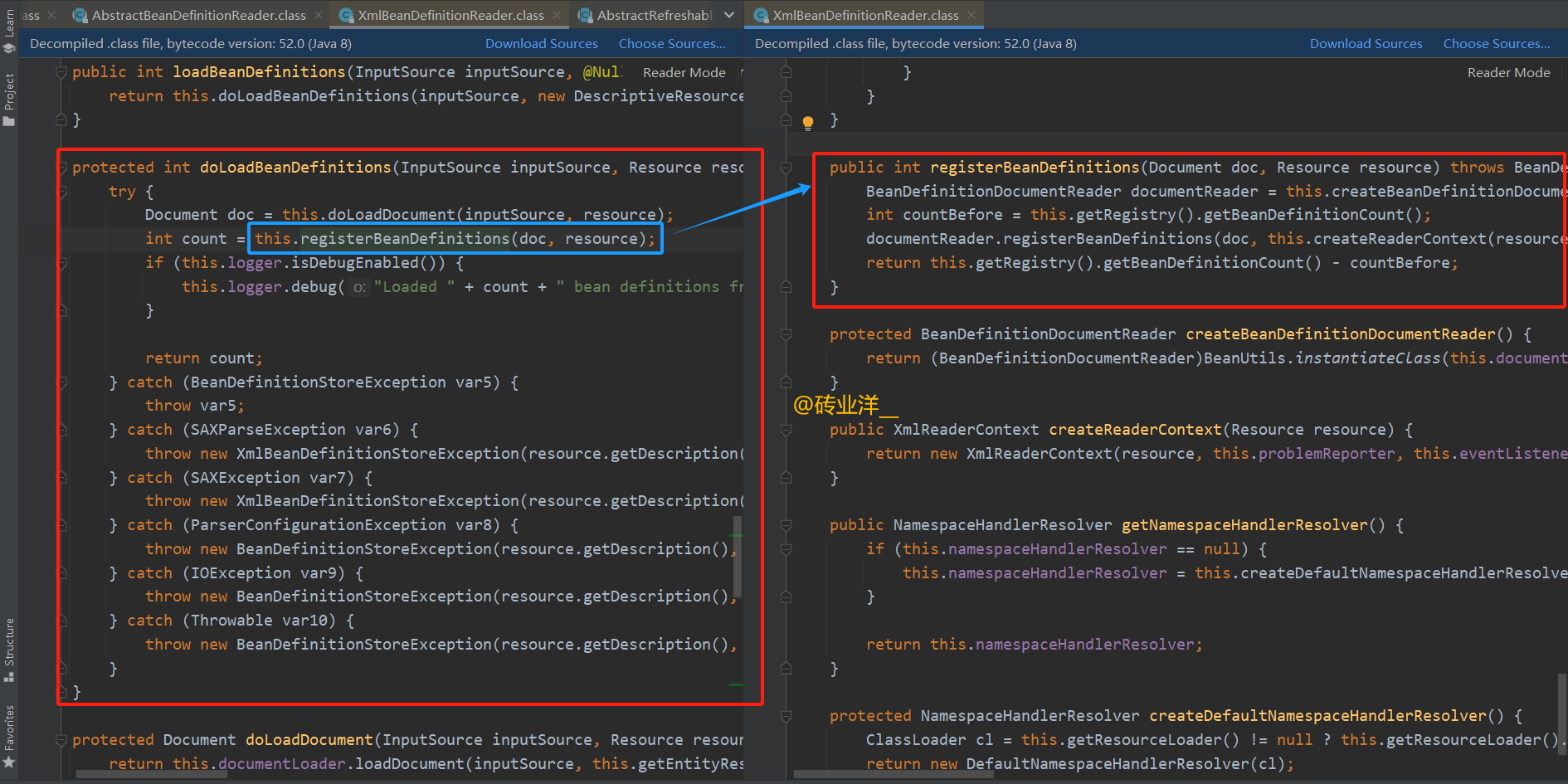
doLoadBeanDefinitions方法做了什么?
具体步骤如下:
使用doLoadDocument方法将给定的InputSource解析为 DOM Document对象。这个Document对象代表了 XML 文件的结构。
通过调用registerBeanDefinitions方法,将解析得到的Document中的 Bean 定义注册到 Spring 的 Bean 工厂中。这个方法返回注册的 Bean 定义的数量。
如果日志级别设置为 DEBUG,则会记录加载的 Bean 定义数量。
这里重点是registerBeanDefinitions方法,继续跟踪代码
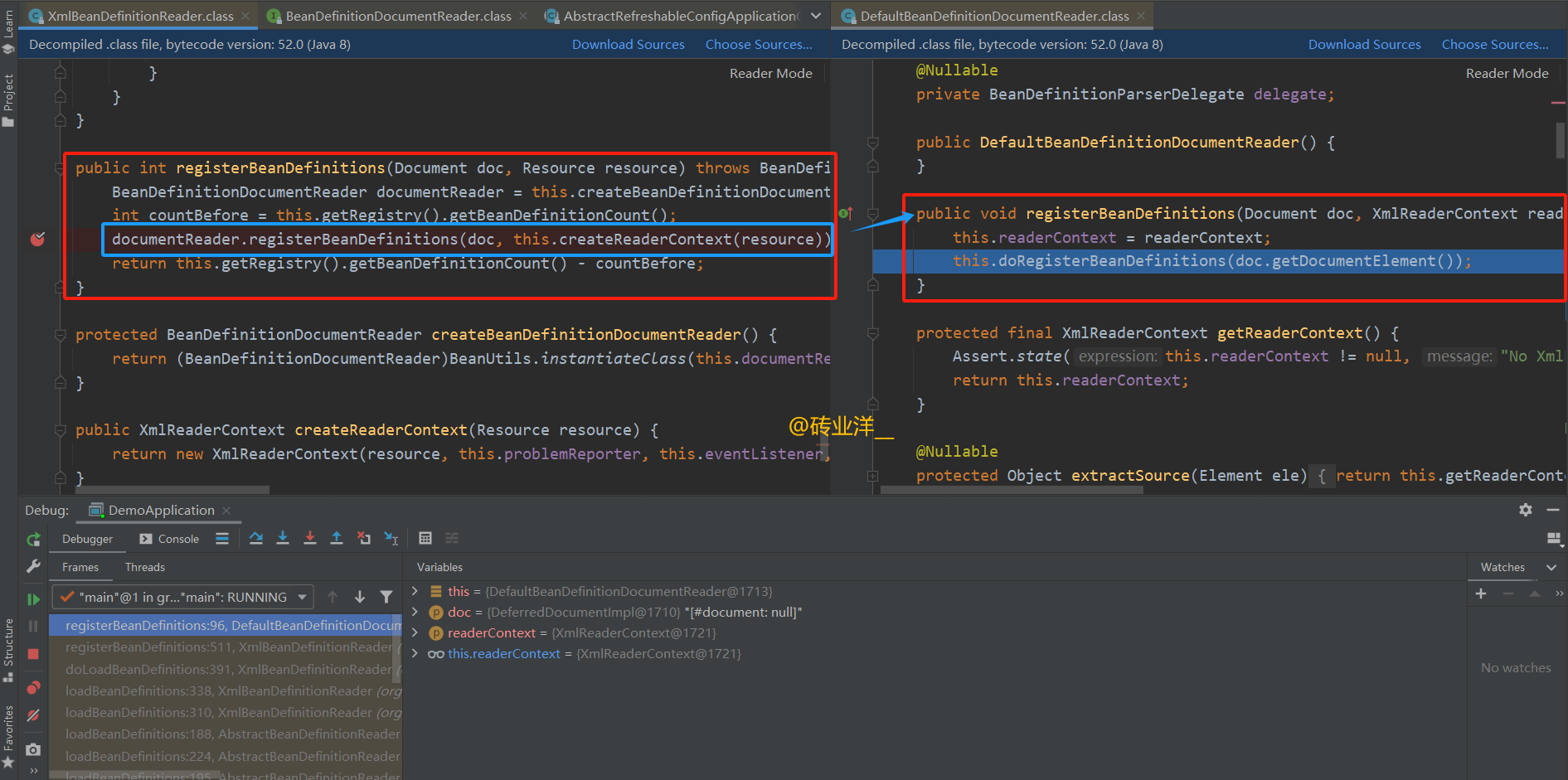
继续看重点,最终追到doRegisterBeanDefinitions方法
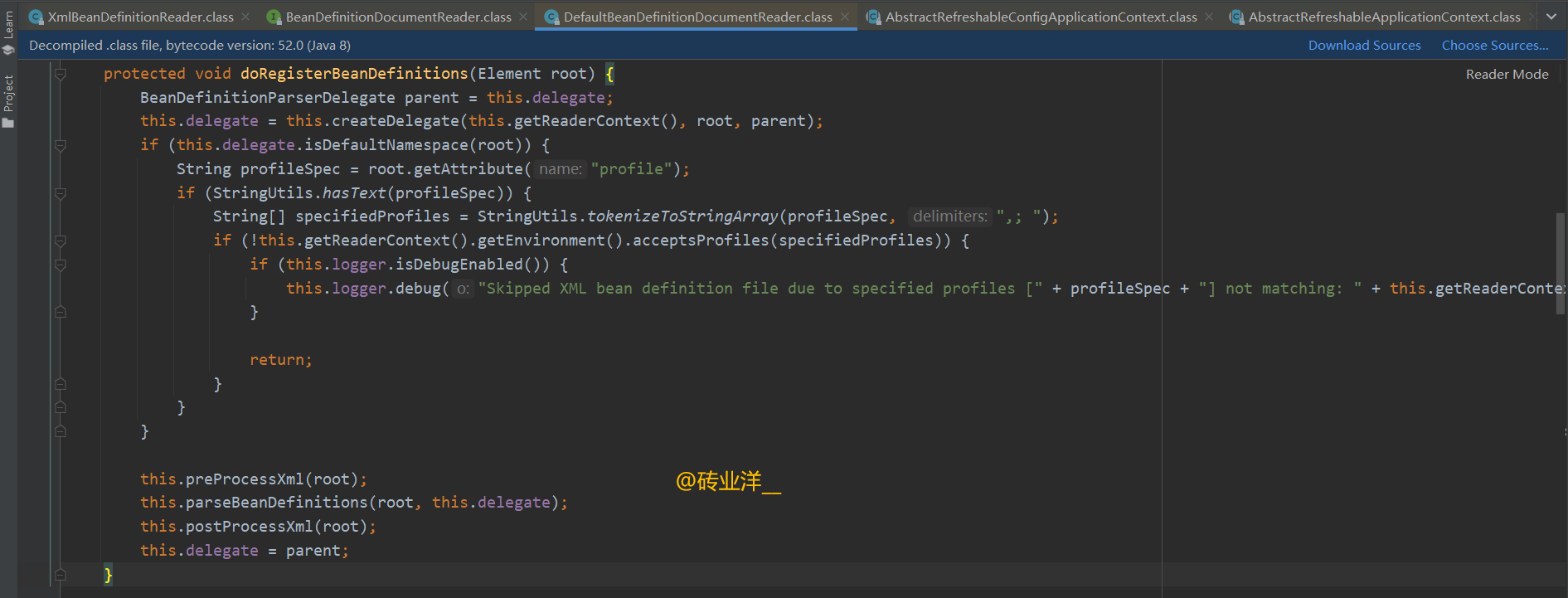
doRegisterBeanDefinitions(Element root) 方法是 Spring 框架中用于解析 XML 配置文件中的 Bean 定义并注册它们到 Spring 容器的方法。这个方法通常在 XML 文件读取并转换成 DOM(Document Object Model)树之后调用,此时 XML 文件的根元素通过参数 root 传递给这个方法。
代码提出来分析:
protected void doRegisterBeanDefinitions(Element root) {
// 保存旧的解析代理(delegate),以便之后可以恢复
BeanDefinitionParserDelegate parent = this.delegate;
// 创建新的解析代理(delegate),用于处理当前XML根节点的解析
this.delegate = this.createDelegate(this.getReaderContext(), root, parent);
// 如果当前节点使用的是Spring默认的XML命名空间
if (this.delegate.isDefaultNamespace(root)) {
// 获取根节点的"profile"属性
String profileSpec = root.getAttribute("profile");
// 检查"profile"属性是否有文本内容
if (StringUtils.hasText(profileSpec)) {
// 按逗号、分号和空格分隔"profile"属性值,得到指定的profiles数组
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(profileSpec, ",; ");
// 如果当前环境不接受任何指定的profiles,则不加载该Bean定义文件
if (!this.getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
// 如果日志级别是DEBUG,则记录跳过文件的信息
if (this.logger.isDebugEnabled()) {
this.logger.debug("Skipped XML bean definition file due to specified profiles [" + profileSpec + "] not matching: " + this.getReaderContext().getResource());
}
// 退出方法,不进行后续处理
return;
}
}
}
// 在解析XML前进行预处理,可被重写的方法
this.preProcessXml(root);
// 解析XML根节点下的Bean定义
this.parseBeanDefinitions(root, this.delegate);
// 在解析XML后进行后处理,可被重写的方法
this.postProcessXml(root);
// 恢复旧的解析代理(delegate)
this.delegate = parent;
}
上述代码片段是Spring框架用于注册Bean定义的内部方法。该方法在解析XML配置文件并注册Bean定义到Spring容器时被调用。它包含处理profile属性以根据运行时环境决定是否加载特定Bean定义的逻辑,以及前后处理钩子,允许在解析前后进行自定义操作。最后,它确保解析代理(delegate)被重置为之前的状态,以维护正确的状态。
接着,我们要看看是如何解析xml的,重点关注下parseBeanDefinitions方法
2.7 parseBeanDefinitions – 解析XML中的BeanDefinition元素
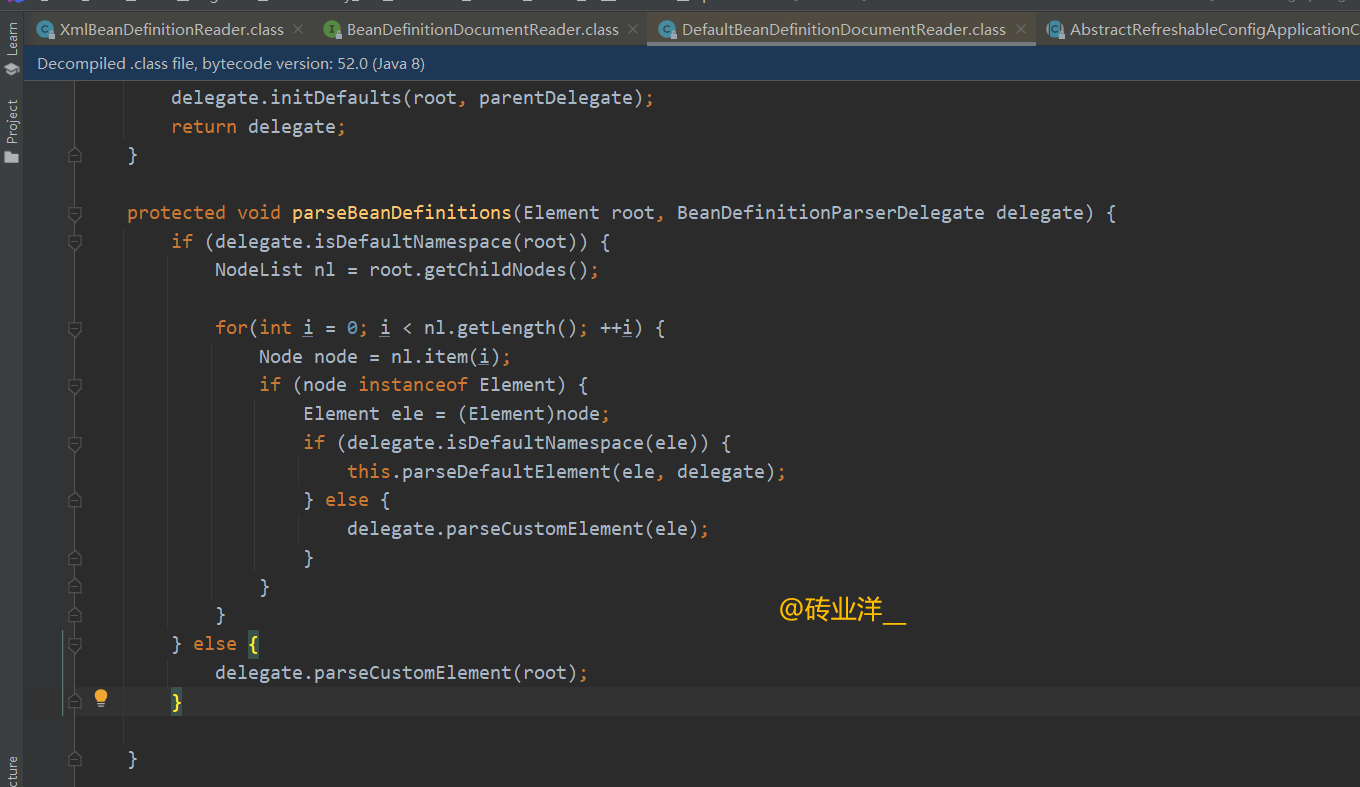
parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) 方法的主要目的是遍历 XML 配置文件的根节点,解析并注册其中定义的所有 Bean。该方法负责区分不同类型的元素,即默认命名空间下的标准元素和自定义命名空间下的自定义元素,并对它们进行相应的处理。
代码提出来分析:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 判断根节点是否使用的是Spring的默认命名空间
if (delegate.isDefaultNamespace(root)) {
// 获取所有子节点
NodeList nl = root.getChildNodes();
// 遍历所有子节点
for (int i = 0; i < nl.getLength(); ++i) {
Node node = nl.item(i);
// 只处理Element类型的节点(过滤掉文本节点等其他类型)
if (node instanceof Element) {
Element ele = (Element)node;
// 如果子元素节点也是默认命名空间,则调用parseDefaultElement方法解析
if (delegate.isDefaultNamespace(ele)) {
this.parseDefaultElement(ele, delegate);
} else {
// 如果子元素节点不是默认命名空间,则调用parseCustomElement方法解析
// 这通常表示节点定义了自定义的行为,可能是用户自定义的标签或者是Spring扩展的标签
delegate.parseCustomElement(ele);
}
}
}
} else {
// 如果根节点不是默认命名空间,那么它可能是一个自定义标签的顶级元素
// 在这种情况下,直接调用parseCustomElement进行解析
delegate.parseCustomElement(root);
}
}
这段代码的作用是解析XML文件中定义的bean。它检查每个XML元素(包括根元素和子元素),并根据这些元素是否属于Spring的默认命名空间(通常是”http://www.springframework.org/schema/beans“),调用不同的处理方法。如果元素属于默认命名空间,那么它将调用parseDefaultElement来解析标准的Spring配置元素,例如。如果元素不属于默认命名空间,那么将认为它是一个自定义元素,并调用parseCustomElement来解析。自定义元素通常是由开发人员定义或Spring扩展提供的,以增加框架的功能。
这里可以看到是一个循环处理Element节点,解析的动作主要是parseDefaultElement方法,继续来看看。
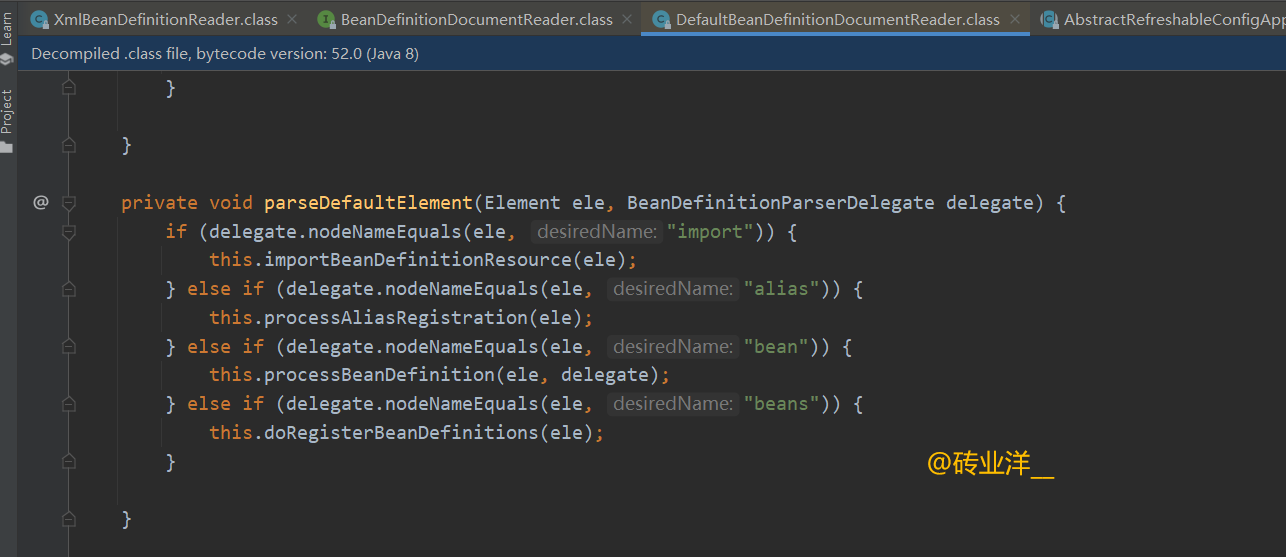
parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) 方法是 Spring 框架解析 XML 配置文件中默认命名空间(也就是没有前缀的 Spring 命名空间)元素的方法。这个方法专门处理 , , , 和 这几种标签。
“没有前缀的 Spring 命名空间” 是指那些元素?它们属于 Spring 的默认命名空间,但在使用时不需要指定命名空间前缀。如 , 或 ,这些元素都是没有前缀的,它们属于 Spring 默认定义的 XML 模式命名空间,默认命名空间通常在 XML 文件的顶部通过 xmlns 属性声明。
代码提出来分析:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// 判断当前元素节点名称是否是"import"
if (delegate.nodeNameEquals(ele, "import")) {
// 如果是"import",则导入其他配置文件
this.importBeanDefinitionResource(ele);
} else if (delegate.nodeNameEquals(ele, "alias")) {
// 如果节点是"alias",则处理别名定义,为一个bean定义一个或多个别名
this.processAliasRegistration(ele);
} else if (delegate.nodeNameEquals(ele, "bean")) {
// 如果节点是"bean",则处理bean定义,这是定义Spring bean的核心元素
this.processBeanDefinition(ele, delegate);
} else if (delegate.nodeNameEquals(ele, "beans")) {
// 如果节点是"beans",意味着有嵌套的beans定义,需要递归地注册其中的bean定义
this.doRegisterBeanDefinitions(ele);
}
}
这段代码的功能是根据元素的名称来决定对XML配置文件中的不同标签进行不同的处理操作。它处理Spring框架默认命名空间下的四种主要标签:
:导入其他Spring XML配置文件到当前的配置文件中。
:为一个已经定义的bean提供一个或多个别名。
:定义一个Spring管理的bean,是最常用的元素,包含了bean的详细配置。
:定义一个beans的集合,通常是配置文件中的顶层元素,但也可以是嵌套定义,表示一个新的作用域或者上下文。
这样,Spring可以根据这些元素来构建应用上下文中的bean工厂。
调试可以发现,xml已经解析出初步的雏形了

在这里似乎没看到bean元素,这是怎么解析的呢?让我们一步一步来,在上面提到的parseDefaultElement方法中有调用processBeanDefinition方法,来看看这是干嘛的。
2.8 processBeanDefinition – 对
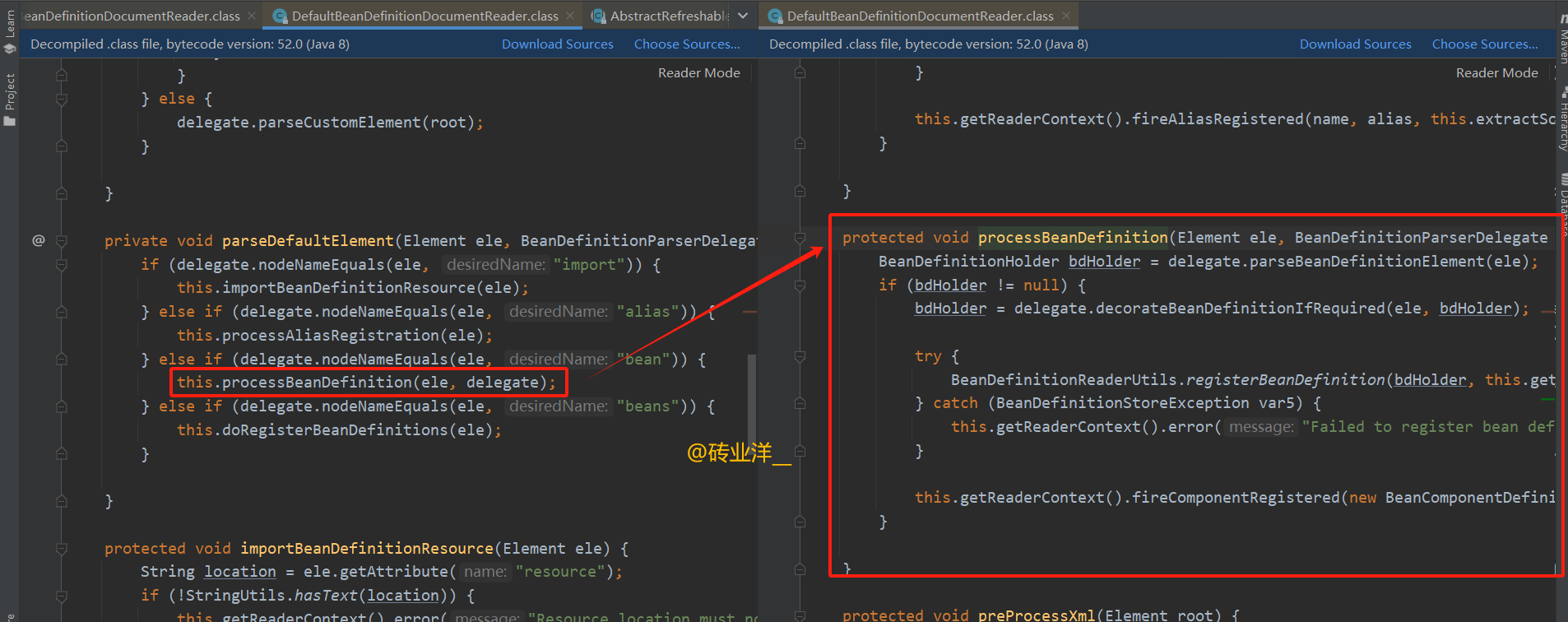
processBeanDefinition方法是 Spring 框架中用于处理 XML 配置元素的方法。其目的是将 元素中描述的信息转换为 Spring 内部使用的BeanDefinition对象,并将其注册到 Spring IoC 容器中。这是 Spring bean 生命周期中的一个关键步骤,因为在这里定义的 bean 会在容器启动时被实例化和管理
代码提出来分析:
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 使用代理解析bean定义元素,这涉及将XML定义的元素转换成Spring的BeanDefinitionHolder对象,
// 该对象包含了bean定义和名称。
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
// 检查解析是否返回了BeanDefinitionHolder对象。
if (bdHolder != null) {
// 如有需要,对bean定义进行装饰。这可能涉及应用任何额外的属性或嵌套元素,
// 这些都是bean定义的一部分,但不是标准 XML配置的一部分。
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 在注册中心注册bean定义。注册中心通常是持有所有bean定义的Spring IoC容器。
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, this.getReaderContext().getRegistry());
} catch (BeanDefinitionStoreException var5) {
// 如果在bean注册过程中出现异常,报告错误上下文并抛出异常。
// 错误上下文包括bean的名称和引起问题的XML元素。
this.getReaderContext().error("Failed to register bean definition with name '" + bdHolder.getBeanName() + "'", ele, var5);
}
// 在成功注册后,通知任何监听器一个新的bean定义已被注册。
// 这是Spring事件机制的一部分,允许对容器内的特定动作作出响应。
this.getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
// 注意:如果bdHolder为空,则意味着bean定义元素没有被正确解析
// 或者它不是要被注册的(例如,在抽象定义的情况下)。
// 因此,在这种情况下,该方法不执行任何操作。
}
该方法通常在Spring框架的bean定义解析过程中使用,它处理基于提供的XML元素创建和注册bean定义的逻辑。BeanDefinitionParserDelegate 是一个帮助类,负责处理解析特定Spring XML结构的细节。
debug这个类的时候,发现已经解析出这个bean的class和id了
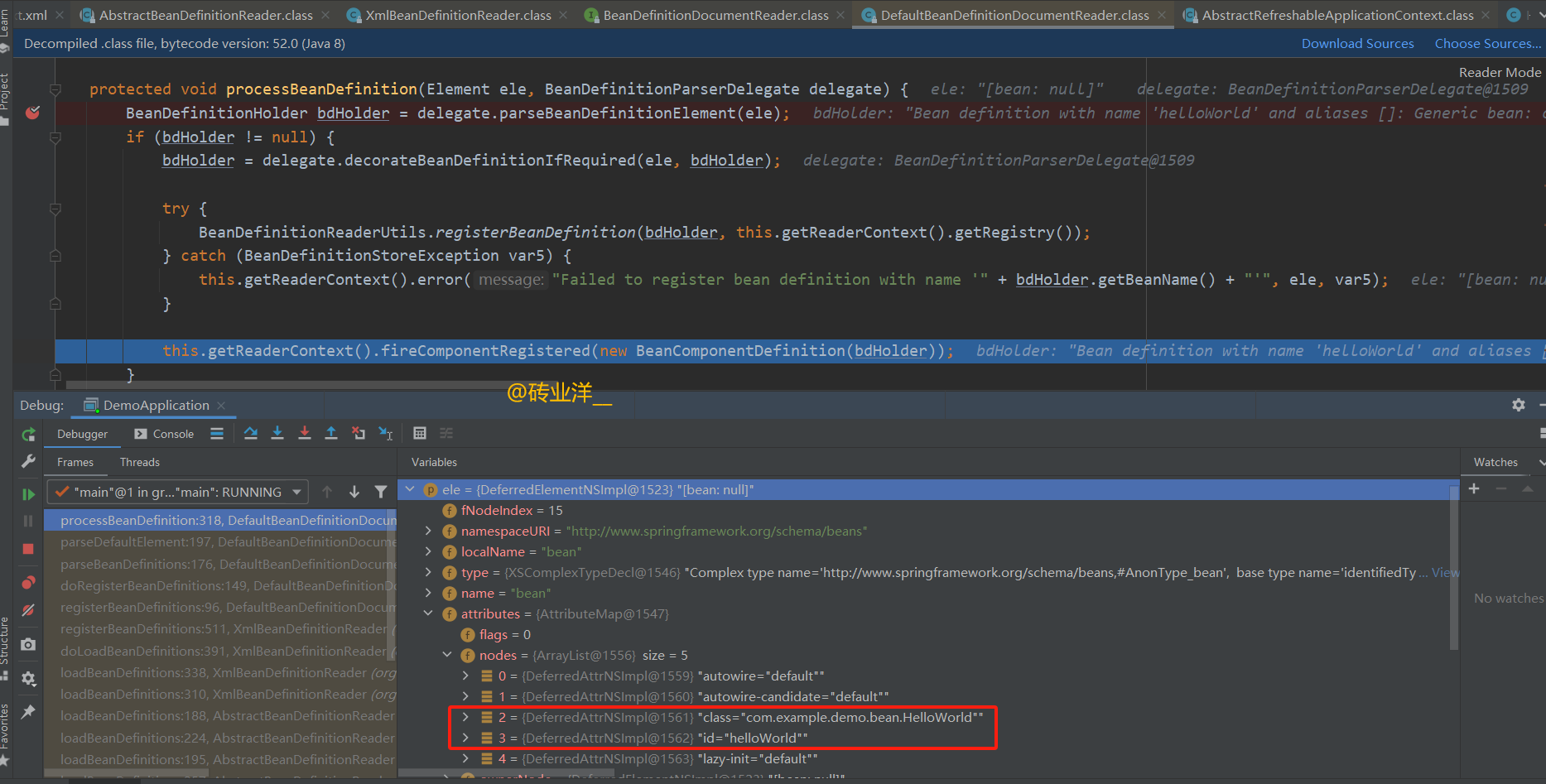
有人会好奇了,这是如何将 xml 元素封装为 BeanDefinitionHolder呢
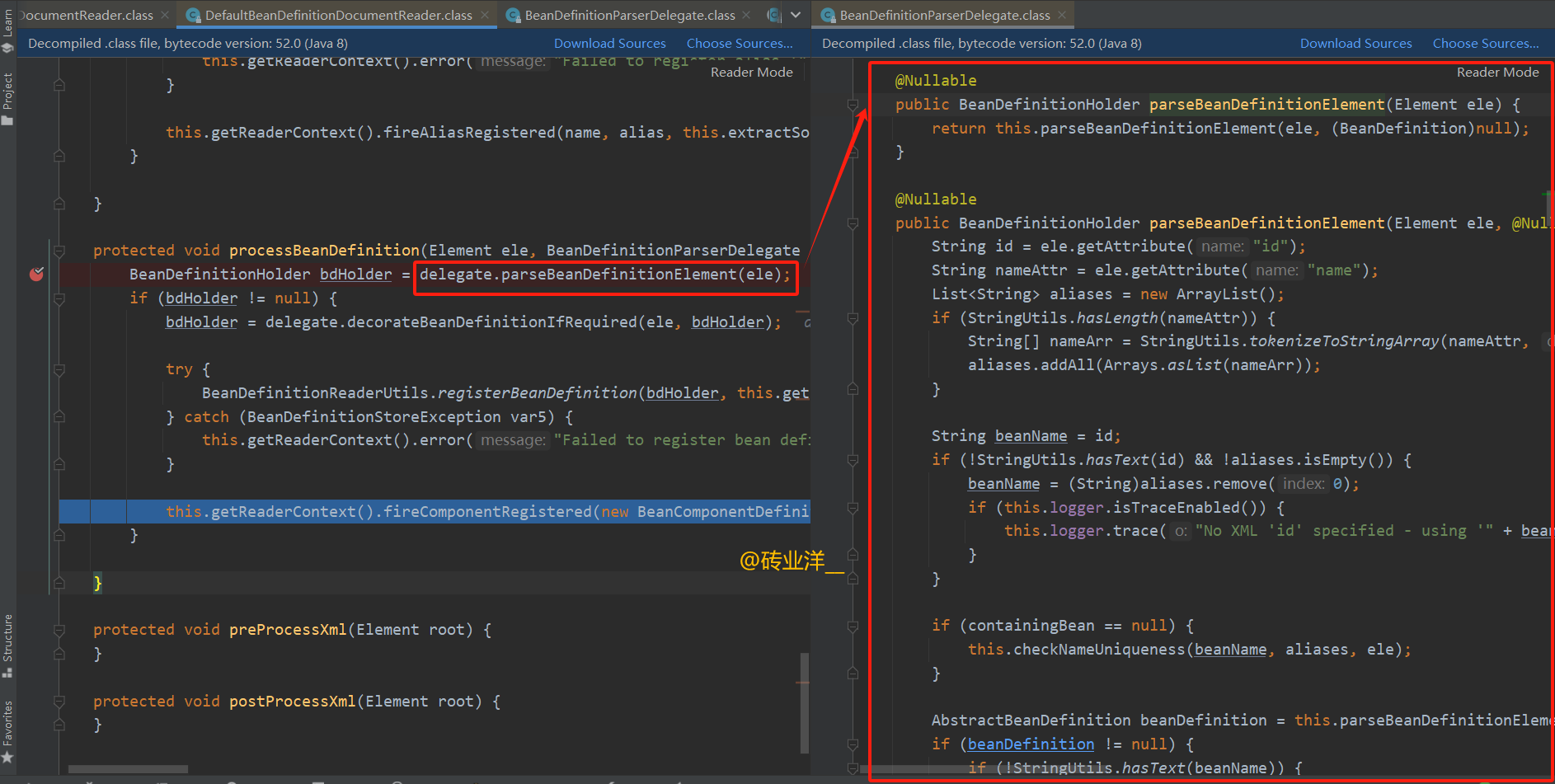
parseBeanDefinitionElement方法是用来解析 Spring 配置文件中 元素的定义,并生成对应的 BeanDefinitionHolder 对象。BeanDefinitionHolder 是一个包装类,它封装了 BeanDefinition 实例和该定义的名称(即bean的id)以及别名(如果有的话)。
代码提出来分析:
@Nullable
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
// 调用重载方法parseBeanDefinitionElement,并将BeanDefinition设置为null
return this.parseBeanDefinitionElement(ele, (BeanDefinition)null);
}
@Nullable
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
// 获取元素的id属性
String id = ele.getAttribute("id");
// 获取元素的name属性
String nameAttr = ele.getAttribute("name");
// 创建别名列表
List aliases = new ArrayList();
if (StringUtils.hasLength(nameAttr)) {
// 如果name属性非空,则使用分隔符分割name字符串,并将结果添加到别名列表
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, ",; ");
aliases.addAll(Arrays.asList(nameArr));
}
// 默认情况下bean的名称使用id属性的值
String beanName = id;
if (!StringUtils.hasText(id) && !aliases.isEmpty()) {
// 如果id为空且别名列表非空,则使用别名列表中的第一个作为bean名称,并从列表中移除它
beanName = aliases.remove(0);
if (this.logger.isTraceEnabled()) {
this.logger.trace("No XML 'id' specified - using '" + beanName + "' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
// 如果不是嵌套bean定义,则检查bean名称和别名的唯一性
this.checkNameUniqueness(beanName, aliases, ele);
}
// 解析bean定义元素,返回AbstractBeanDefinition对象
AbstractBeanDefinition beanDefinition = this.parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
// 如果bean名称为空,则尝试生成bean名称
try {
if (containingBean != null) {
// 如果是内部bean,则使用特定的生成策略
beanName = BeanDefinitionReaderUtils.generateBeanName(beanDefinition, this.readerContext.getRegistry(), true);
} else {
// 否则使用默认策略
beanName = this.readerContext.generateBeanName(beanDefinition);
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null && beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() && !this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
// 如果bean类名不为空,且生成的bean名称以类名开头,且未被使用,则将类名添加到别名列表
aliases.add(beanClassName);
}
}
if (this.logger.isTraceEnabled()) {
this.logger.trace("Neither XML 'id' nor 'name' specified - using generated bean name [" + beanName + "]");
}
} catch (Exception var9) {
// 在名称生成过程中捕获异常,并记录错误
this.error(var9.getMessage(), ele);
return null;
}
}
// 将别名列表转换为数组
String[] aliasesArray = StringUtils.toStringArray(aliases);
// 创建并返回BeanDefinitionHolder对象
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
} else {
// 如果bean定义为空,则返回null
return null;
}
}
这段代码负责解析XML中的元素,提取id和name属性,并处理可能的别名。然后它创建一个AbstractBeanDefinition,这是Spring中bean定义的抽象表现形式。如果没有指定bean的名称,它会尝试生成一个唯一的名称,并在必要时添加别名。最终,它返回一个包含所有这些信息的BeanDefinitionHolder。如果在解析过程中遇到任何问题,会记录错误并返回null。
在这段代码中,会调用另一个重载方法,this.parseBeanDefinitionElement(ele, beanName, containingBean);这段代码里有封装 其它属性的 parseBeanDefinitionAttributes 方法,我们来看下
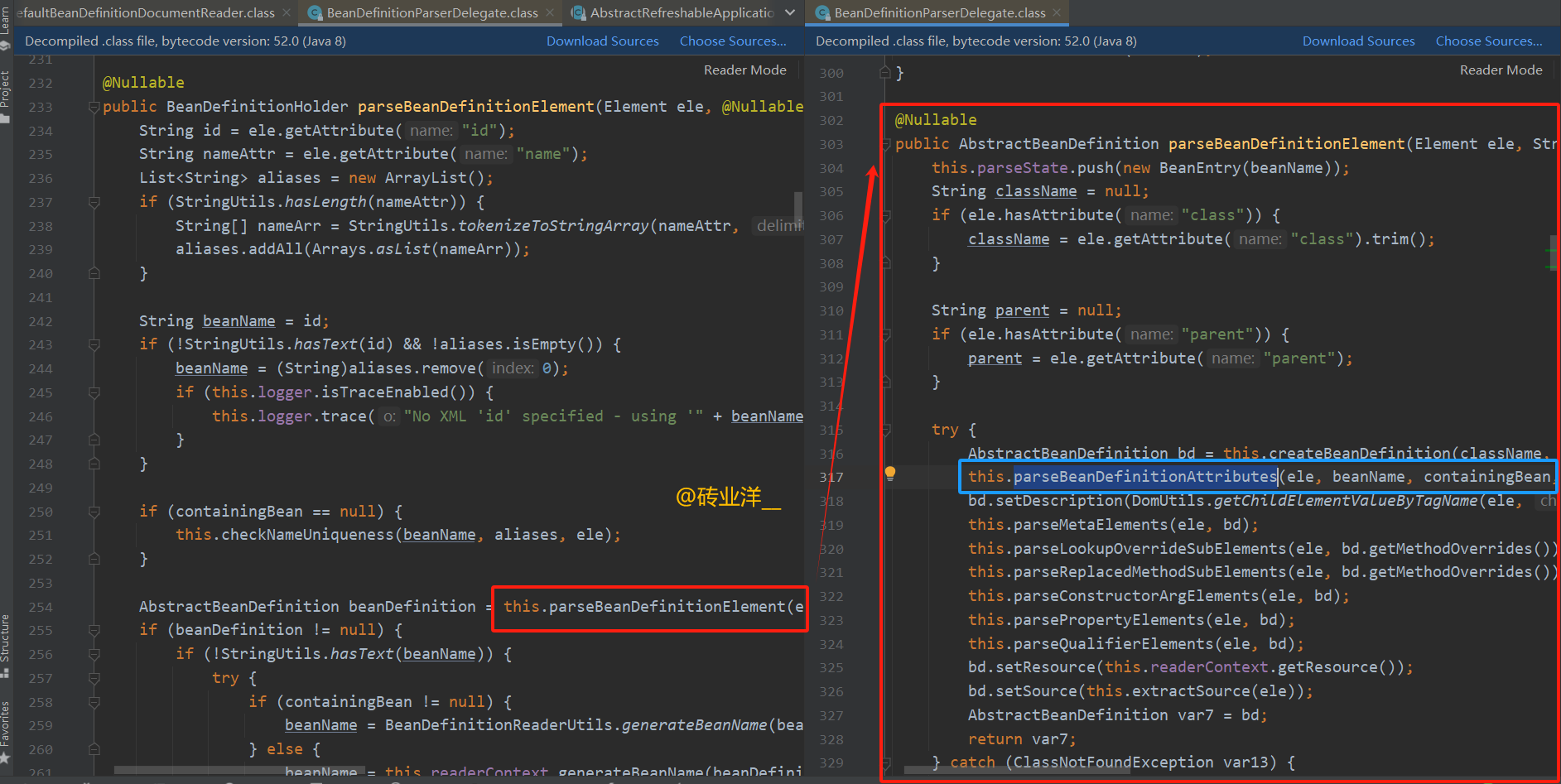
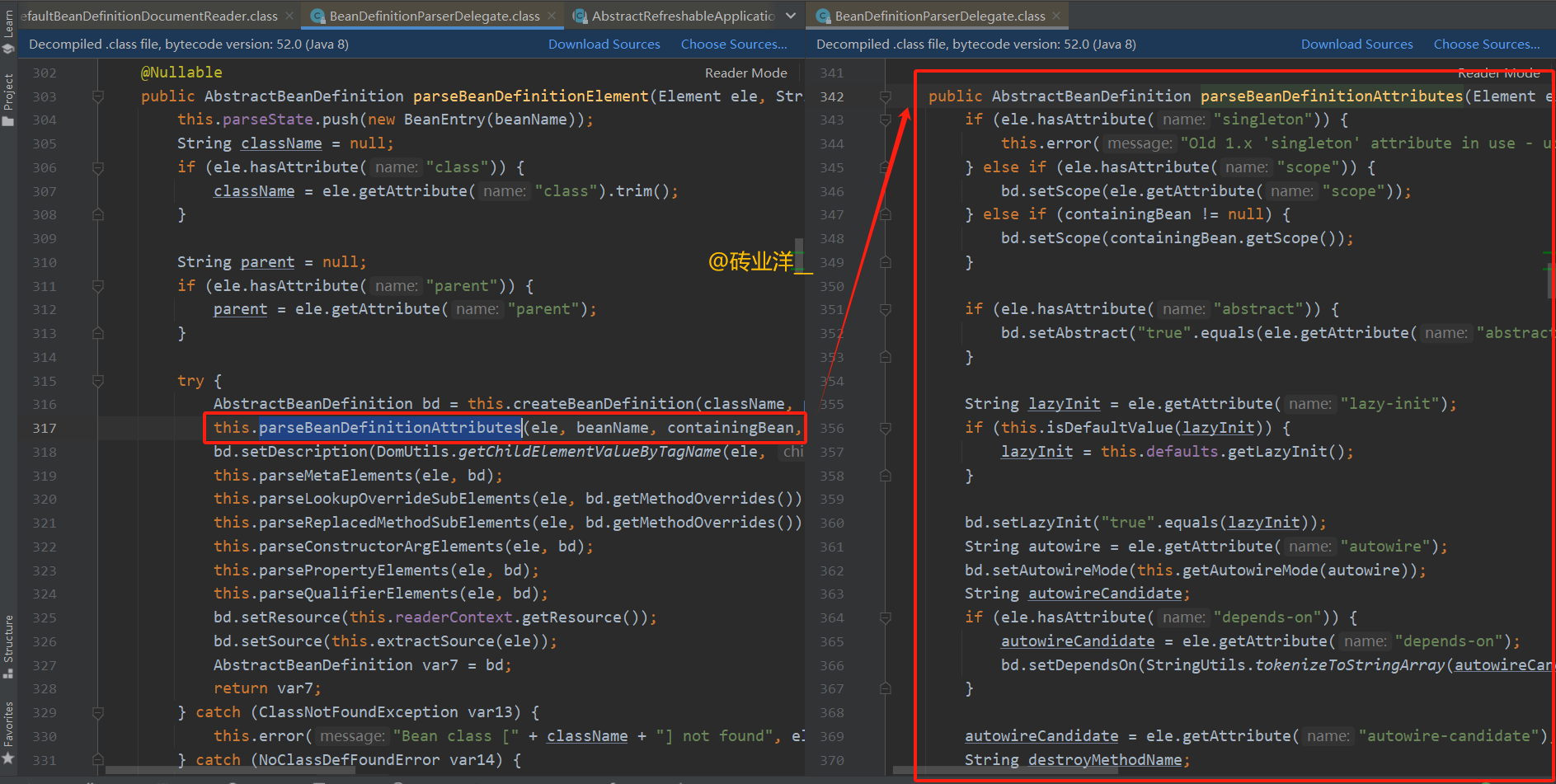
方法 parseBeanDefinitionAttributes 用于解析 Spring 配置文件中 元素的属性,并将这些属性应用到传入的 AbstractBeanDefinition 对象上。这个过程是为了设置bean的作用域、是否延迟初始化、自动装配模式、依赖关系、是否作为自动装配的候选、是否是优先考虑的bean(primary)、初始化方法、销毁方法、工厂方法和工厂bean名称等属性。方法处理了属性的默认值以及处理了一些属性的遗留格式(如 singleton)。
直接提出代码分析:
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName, @Nullable BeanDefinition containingBean, AbstractBeanDefinition bd) {
// 检查是否使用了已废弃的singleton属性,如果存在,则报错提示应该升级到scope属性
if (ele.hasAttribute("singleton")) {
this.error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);
// 如果存在scope属性,则设置bean的作用域
} else if (ele.hasAttribute("scope")) {
bd.setScope(ele.getAttribute("scope"));
// 如果没有设置scope属性但是有包含bean,则设置为包含bean的作用域
} else if (containingBean != null) {
bd.setScope(containingBean.getScope());
}
// 如果设置了abstract属性,根据该属性的值设置bean定义是否为抽象
if (ele.hasAttribute("abstract")) {
bd.setAbstract("true".equals(ele.getAttribute("abstract")));
}
// 解析lazy-init属性,默认使用配置的默认值,如果设置了则覆盖
String lazyInit = ele.getAttribute("lazy-init");
if (this.isDefaultValue(lazyInit)) {
lazyInit = this.defaults.getLazyInit();
}
bd.setLazyInit("true".equals(lazyInit));
// 解析autowire属性,将字符串值转换为相应的自动装配模式
String autowire = ele.getAttribute("autowire");
bd.setAutowireMode(this.getAutowireMode(autowire));
// 解析depends-on属性,将字符串值转换为数组,并设置为bean定义的依赖
if (ele.hasAttribute("depends-on")) {
String dependsOn = ele.getAttribute("depends-on");
bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, ",; "));
}
// 解析autowire-candidate属性,设置bean是否可作为自动装配的候选者
String autowireCandidate = ele.getAttribute("autowire-candidate");
if (this.isDefaultValue(autowireCandidate)) {
String defaultValue = this.defaults.getAutowireCandidates();
if (defaultValue != null) {
String[] patterns = StringUtils.commaDelimitedListToStringArray(defaultValue);
bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));
}
} else {
bd.setAutowireCandidate("true".equals(autowireCandidate));
}
// 解析primary属性,设置bean是否为primary
if (ele.hasAttribute("primary")) {
bd.setPrimary("true".equals(ele.getAttribute("primary")));
}
// 解析init-method属性,设置bean的初始化方法
String initMethodName = ele.getAttribute("init-method");
if (ele.hasAttribute("init-method")) {
bd.setInitMethodName(initMethodName);
// 如果没有设置但是有默认值,则使用默认值
} else if (this.defaults.getInitMethod() != null) {
bd.setInitMethodName(this.defaults.getInitMethod());
bd.setEnforceInitMethod(false);
}
// 解析destroy-method属性,设置bean的销毁方法
String destroyMethodName = ele.getAttribute("destroy-method");
if (ele.hasAttribute("destroy-method")) {
bd.setDestroyMethodName(destroyMethodName);
// 如果没有设置但是有默认值,则使用默认值
} else if (this.defaults.getDestroyMethod() != null) {
bd.setDestroyMethodName(this.defaults.getDestroyMethod());
bd.setEnforceDestroyMethod(false);
}
// 解析factory-method属性,设置bean的工厂方法
if (ele.hasAttribute("factory-method")) {
bd.setFactoryMethodName(ele.getAttribute("factory-method"));
}
// 解析factory-bean属性,设置bean的工厂bean名
if (ele.hasAttribute("factory-bean")) {
bd.setFactoryBeanName(ele.getAttribute("factory-bean"));
}
// 返回配置好的bean定义
return bd;
}
这段代码的核心功能是将XML配置文件中的属性转换为BeanDefinition对象的属性。对于每个属性,它首先检查该属性是否存在,如果存在,则读取其值并设置到BeanDefinition对象中。如果存在默认值,并且XML中没有提供特定值,则使用默认值。通过这种方式,Spring容器能够根据配置文件创建和管理bean。
2.9 总结
从读取XML配置文件到注册BeanDefinition的完整流程:
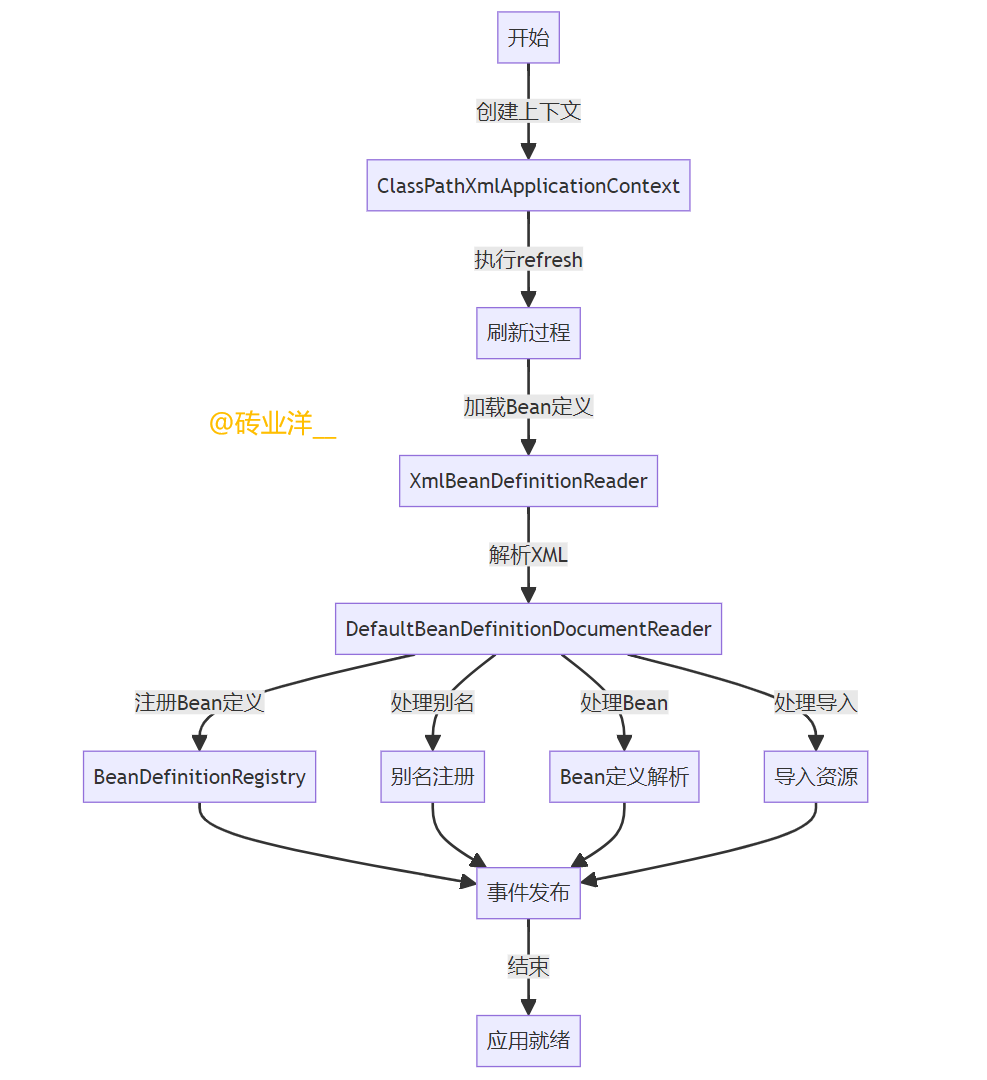
加载配置文件:
图中”创建上下文”步骤对应于实例化ClassPathXmlApplicationContext,这时会传入XML文件路径。
ClassPathXmlApplicationContext接受一个或多个XML文件路径作为构造参数。
初始化BeanFactory并进行刷新:
在图中”执行refresh“步骤表示refresh()方法被调用,这个方法会启动容器的初始化和刷新过程。
在refresh()方法中初始化BeanFactory,并准备对配置文件进行解析。
读取XML配置文件:
图中”加载Bean定义”步骤代表XmlBeanDefinitionReader的作用,它负责读取和加载XML配置文件。
XmlBeanDefinitionReader 负责读取传入的XML配置文件。
解析XML文件:
图中的”解析XML“步骤表示DefaultBeanDefinitionDocumentReader处理XML文件,这包括解析顶层标签。
DefaultBeanDefinitionDocumentReader 开始处理XML文件,解析这样的顶层标签。
对于元素的解析,首先检查元素是否在默认命名空间。如果是,进行默认元素的解析;如果不是,默认命名空间之外的元素被认为是自定义元素,并交由delegate.parseCustomElement(ele)处理。
Bean定义的解析和注册:
图中的”注册Bean定义”、“处理别名”、“处理Bean”和“处理导入”步骤对应于BeanDefinitionParserDelegate的各种解析活动,它涉及解析bean的id、name、别名、属性、子元素等,以及将解析结果注册到BeanDefinitionRegistry。
使用BeanDefinitionParserDelegate来解析元素的细节,包括bean的id、name、别名等。
解析元素的属性,如scope、lazy-init等,并将这些值设置到BeanDefinition实例中。
如果元素包含子元素(如或),它们也将被解析并以相应的元数据形式加入到BeanDefinition中。
生成的BeanDefinition将会注册到BeanDefinitionRegistry中,使用BeanDefinitionReaderUtils.registerBeanDefinition方法。
如果解析过程中发生任何错误,会通过error方法记录错误信息。
事件发布:
在注册BeanDefinition后,ApplicationContext会发布一个组件注册事件,以通知相关的监听器。这个过程允许实现了ApplicationListener接口或使用@EventListener注解的组件接收到这个事件,并根据需要进行响应。例如,可以使用这个事件来触发某些自定义的逻辑,如额外的配置检查、启动某些后处理操作等。
这个详细流程显示了从加载配置文件到解析并注册BeanDefinition所涉及的复杂过程,它展示了Spring框架处理Bean声明和依赖关系的内部机制。这是Spring依赖注入核心功能的基础,确保了Bean能够按照定义被实例化和管理。
3. 源码阅读练习题
1. XML配置文件解析:
解析Spring配置文件时,Spring容器使用了哪些组件?
Spring容器在解析配置文件时主要使用了 XmlBeanDefinitionReader 类。此外,还用到了 BeanDefinitionDocumentReader 来进行具体的文档读取。
BeanDefinitionReader 在配置文件解析中扮演什么角色?
BeanDefinitionReader 负责从XML文件读取bean定义并转换为Spring内部的 BeanDefinition 对象。
parseBeanDefinitionElement 方法是在什么时候被调用的?它的输出是什么?
parseBeanDefinitionElement 在XML元素被读取时调用,它的输出是 BeanDefinitionHolder 对象,其中包含了bean定义以及名称和别名。
2. Bean定义解析:
描述一个bean定义从读取XML元素开始,到生成 BeanDefinition 对象的过程。
BeanDefinition 对象是通过读取XML中的 元素并提取相关属性来创建的。这些属性包括bean的类名、作用域、生命周期回调等。
parseBeanDefinitionAttributes 方法在整个解析过程中的作用是什么?
parseBeanDefinitionAttributes 方法用于提取bean元素上的属性,并设置到 AbstractBeanDefinition 对象中。
哪些XML属性会被 parseBeanDefinitionAttributes 方法处理,并如何影响生成的 BeanDefinition 对象?
parseBeanDefinitionAttributes 方法处理的属性包括 scope、lazy-init、autowire 等,这些属性会决定bean的行为和它如何与其他bean交互。
3. Bean名称与别名:
如果XML元素中没有提供bean的id或name,Spring是如何处理的?
如果没有提供id或name,Spring会自动生成一个唯一的bean名称。它可能基于类名加上一定的序列号。提示:分析parseBeanDefinitionElement方法时有说过。
别名(alias)在Spring中有何用途?在 parseBeanDefinitionElement 方法中,别名是如何被处理的?
别名可以为bean提供额外的名称,这在需要引用相同的bean但在不同上下文中使用不同名称时很有用。在 parseBeanDefinitionElement 方法中,别名是通过解析 name 属性并以逗号、分号或空格作为分隔符来处理的。
4. Bean作用域与生命周期属性:
如何定义一个bean的作用域(scope)?singleton 和 prototype 有什么不同?
通过设置 元素的 scope 属性定义bean的作用域。singleton 表示全局唯一实例,而 prototype 表示每次请求都创建一个新的实例。
lazy-init、init-method 和 destroy-method 这些属性对bean的生命周期有什么影响?
lazy-init 属性确定bean是否应该在启动时延迟初始化,init-method 和 destroy-method 定义了bean的初始化和销毁时调用的方法。
5. Bean注册:
一旦 BeanDefinition 对象被创建,Spring是如何将其注册到容器中的?
BeanDefinition 对象在解析后,通过 DefaultListableBeanFactory.registerBeanDefinition 方法注册到Spring容器中。
注册过程中,如果发现bean名称冲突,Spring会如何处理?
如果发现名称冲突,会抛出 BeanDefinitionStoreException。如果是在不同的配置文件中定义相同名称的bean,后者通常会覆盖前者。
6. 异常处理:
当XML配置不正确或使用了不合法的属性时,Spring是如何反馈给用户的?
Spring会通过抛出 BeanDefinitionStoreException 来告知用户配置错误。异常信息会详细说明错误的原因和位置。
分析Spring中的错误处理机制,它对于开发者调试配置有何帮助?
Spring的错误处理机制包括异常的详细信息和精确的定位,这对于开发者快速识别配置错误非常有帮助。
4. 常见疑问
4.1 在refresh过程中,Bean的生命周期是怎样的?每个Bean的状态是如何被管理的?
实例化BeanFactory:
在refresh方法开始时,Spring会实例化一个新的BeanFactory,通常是DefaultListableBeanFactory,作为容器用于创建Bean实例。
加载Bean定义:
然后,refresh调用loadBeanDefinitions来加载和注册Bean的定义。这些定义可以来源于XML配置文件、Java配置类或者扫描的注解。
BeanFactoryPostProcessor的执行:
在所有Bean定义加载完成之后,但在Bean实例化之前,Spring会调用BeanFactoryPostProcessor。这些处理器可以对Bean定义(配置元数据)进行修改。
BeanPostProcessor的注册:
接下来,Spring注册BeanPostProcessor实例。这些处理器可以对Bean的实例(创建和初始化后的对象)进行修改。
单例Bean的预实例化:
随后,Spring会预实例化单例Bean。对于单例作用域的Bean,Spring会创建并配置这些Bean,然后将它们放入缓存中。
依赖注入:
在Bean实例化后,Spring会进行依赖注入。此时,Bean的属性将被设置,相关的依赖将被注入。
Bean初始化:
之后,Bean将被初始化。如果Bean实现了InitializingBean接口,afterPropertiesSet方法会被调用;或者如果定义了init-method,指定的方法也会被调用。
Aware接口的调用:
如果Bean实现了任何Aware接口,如ApplicationContextAware或BeanNameAware,它们将在初始化之前被调用。
BeanPostProcessor的后处理:
BeanPostProcessor的前置处理(postProcessBeforeInitialization)和后置处理(postProcessAfterInitialization)方法在Bean初始化之前和之后被调用,它们可以进一步定制Bean。
事件发布:
一旦所有单例Bean都被初始化,Spring会发布ContextRefreshedEvent,表明ApplicationContext已被刷新。
使用Bean:
此时,所有的Bean都准备就绪,并可以用于应用程序的其他部分。
关闭容器:
当应用上下文被关闭时,如果Bean实现了DisposableBean接口,destroy方法会被调用;或者定义了destroy-method方法,它也会被执行来清理资源。
在整个生命周期过程中,每个Bean的状态被ApplicationContext和BeanFactory跟踪和管理,从创建、依赖注入、初始化,到销毁,确保Bean在正确的时机被创建和清理。
4.2 refresh方法是自动触发的吗?如果不是,那么是什么条件下需要手动触发?
在Spring中的refresh方法:
1. 何时触发:
自动触发: 在初始化ApplicationContext的时候,比如在应用程序中使用new ClassPathXmlApplicationContext("config.xml"),Spring容器启动过程中会自动调用refresh方法。
手动触发: 如果在应用程序运行时需要重新加载配置(可能是修改了配置文件),可以手动调用refresh方法来实现。但这通常在开发或测试阶段用于特殊场景,因为它会导致整个应用上下文重建,包括所有的Bean对象。
2. 为什么需要手动触发:
通常情况下,Spring容器在启动时只需要加载一次配置,初始化一次每个Bean。除非有特殊需求,例如动态调整日志级别,重新加载配置文件中的特定Bean,否则不需要手动触发。
在Spring Boot中的refresh方法:
Spring Boot大大简化了Spring应用的配置和启动过程。它自动配置了Spring的ApplicationContext并在合适的时候调用了refresh方法。
1. 自动触发:
当使用Spring Boot的SpringApplication.run()方法启动应用时,Spring Boot会自动创建ApplicationContext,并在内部调用refresh方法。这个过程是自动的,开发者通常不需要关心。
2. 可能的手动触发场景:
Spring Boot提供了actuator模块,其中/refresh端点可以用来重新加载配置(通常是与Spring Cloud Config结合使用)。这不是传统意义上的调用ApplicationContext的refresh方法,而是一种触发重新加载部分配置的机制,特别是标注了@RefreshScope的Bean,它们可以在不重新启动整个应用的情况下更新。
一般情况下的建议:
对于开发者来说,不应该在生产环境中随意手动调用refresh方法。因为这会导致整个应用的重新加载,影响性能并可能导致服务中断。
如果需要动态更新配置,应当使用Spring Cloud Config和Spring Boot Actuator的/refresh端点,这是一种更加安全和控制的方式来更新配置。
4.3 在Spring Boot中,refresh方法的行为是否有所不同?Spring Boot是否提供了更优的方法来处理应用上下文的变化?
在Spring Boot中,refresh方法的基本行为保持不变,因为Spring Boot建立在Spring之上,遵循相同的基本原则。不过,Spring Boot确实为应用上下文的管理和刷新提供了更多的自动化和便利性:
自动配置:
Spring Boot特有的自动配置特性减少了需要手动刷新的场景。在启动时,它会自动装配Bean,通常不需要显式调用refresh。
外部化配置:
Spring Boot支持强大的外部化配置机制,允许通过配置文件、环境变量等方式来注入配置。这使得改变配置而不需要重新刷新上下文成为可能。
条件刷新:
Spring Boot使用条件注解(如@ConditionalOnClass、@ConditionalOnBean等),这允许上下文根据环境或者特定条件动态调整其配置,减少了需要手动触发refresh的场景。
生命周期管理:
通过SpringApplication类,Spring Boot为应用生命周期提供了额外的管理能力。它处理了许多在传统Spring应用中需要手动完成的任务,如初始化和刷新应用上下文。
Actuator endpoints:
对于运行中的应用,Spring Boot Actuator提供了一系列管理和监控的端点,其中一些可以用来刷新配置(如/refresh端点)或者重启上下文(如/restart端点),这在某些情况下可以替代完整的应用重启。
配置更改监听:
使用Spring Cloud Config的应用可以在配置变化时自动刷新上下文。在配置服务器上的变化可以被监听,并且可以触发客户端上下文的自动刷新,而不需要手动干预。
错误处理:
Spring Boot有一套默认的错误处理机制,特别是在Web应用程序中,它会提供默认的错误页面和/error端点。此外,开发者可以定制错误处理,以适应具体需求。
综上所述,Spring Boot提供了更为自动化的方式来处理应用上下文的变化,很多时候无需手动调用refresh方法。不过,如果需要在运行时动态改变Bean的配置,并希望这些改变立即生效,那么可能还需要使用Spring提供的refresh方法或通过Spring Boot Actuator的相关端点来达成这一目的。
欢迎一键三连~
有问题请留言,大家一起探讨学习
———————-Talk is cheap, show me the code———————–文章来源:华为云社区
